・畳み込みニューラルネットワークを用いた新しい深層学習手法により、1枚の静止画からキャラクターを3Dアニメーション化させることができます。
・画像の中のキャラクターを3Dで歩き出させたり、座らせたり、走らせたり、ジャンプさせたりすることができます。
・アニメーション全体をモニターやVR/AR機器でインタラクティブに見ることができます。
近年、動画から作られる一般的なアニメーションは、いくつもの独創的な効果をもたらしています。また、動画や連続写真ではなく、1枚の画像からアニメーションを作ることでも、魅力的な効果が得られています。
SMPL(Skinned Multi-Person Linear)モデルと深層学習フレームワークが、1枚の画像から3Dのポーズや形状を推定するのに、非常に有用であることがわかっています。これまで、単一画像から作る人物アニメーション技術のほとんどは、主に2Dまたは擬似3Dアニメーションに焦点を当てていました。
最近、ワシントン大学とフェイスブックの研究チームが、静止画や画像を3Dアニメーションに変換できる新しい技術を開発しました。「Photo Wake-Up」と名付けられたこの深層学習手法は、畳み込みニューラルネットワーク(CNN)を用いて、1枚の静止画からキャラクターを3Dアニメーション化します。
前景のキャラクターに命を吹き込む
静止画を特定の順序で動かして動画を作成するシネマグラフと異なり、新システムでは、1枚の画像を入力するだけでフル3Dを作り出すことができます。画像の中のキャラクターを3Dで歩き出させたり、座らせたり、走らせたり、ジャンプさせたりすることができ、アニメーション全体をモニターやVR/ARデバイスでインタラクティブに見ることができます。
さて、この新しい手法がどのように機能するのか、気になりますよね。この手法は下記の5つのステップから成ります。
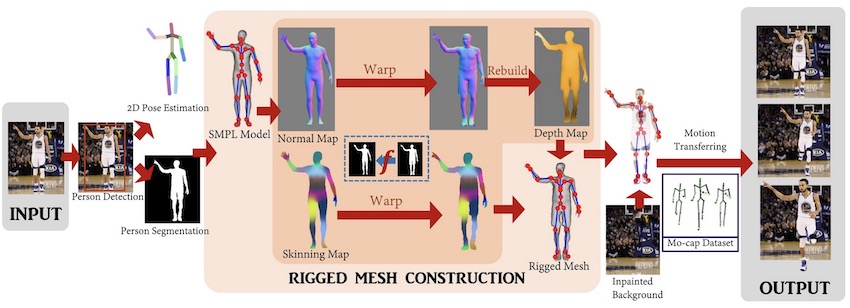
1.モーファブルなボディモデルを画像にフィットさせる
2.ボディラベルマップの推定
3.モーファブルモデルを参考に、段階的にメッシュを作成
4.メッシュをリギングし、メッシュスキンウェイトを推定する
5.最後に、テクスチャを再構築し、白紙の背景画像に貼り付ける
このCNNは、事前に学習されたモデルSMPLに依存しており、NVIDIA TITAN GPUで動作します。また、ポスターやアートからスポーツ写真まで、幅広い正面画像に対応しています。ユーザーは、写真に写っている人物を編集したり、再構成された身体を3Dで見たり、ARデバイスで探索したりすることもできます。例えば、作品を壁に置いて、アニメーションを再生しながらその周りを歩くことができます。
研究チームはこのアルゴリズムを、漫画のキャラクターやグラフィティ、スティーブン・カリー(NBA選手)、ピカソの絵画などの画像で実証しました。これまでに、インターネットからダウンロードした70枚以上の画像でニューラルネットワークのテストを行っています。
比較と検討
研究者たちは、このアルゴリズムを他の最先端の関連手法と比較し、その結果を人間の研究で評価しました。Photo Wake-Upで得られた結果は、他の方法に比べて静止画における歪みが少なく、よりリアルに見えました。さらに、従来の手法では実現できなかった立体感を得ることができました。
このアルゴリズムはまだ完璧とは言えず、改善の余地は大いにあります。例えば、反射や影がまだモデル化されていないため、体全体の形が非現実的に見えるような間違った3Dポーズを生成してしまうことがあります。また、座っているときに足を組む動作など、特定のオクルージョンを改良する必要もあります。