データは、単語数、測定値、変数の説明など、一連の事実である値です。「データ」という用語は、一般に複数形と見なされます。その特異な形式は「データム」であり、単一の変数の単一の値を表します。
データは、以下を含むほぼすべての分野で使用されています。
・金融(債務、金利)
・経営管理(収益、利益率)
・ガバナンス(識字率、失業率)
・非営利団体(ホームレスの数)
・科学研究(観測、実験、派生データ)
文字通り無数の形式のデータがあります。興味深いのは、これらすべてのデータを定量的および定性的な2つのカテゴリに分割できることです。
定量的データ
定量的データは、数値と値を使用して測定できる情報です。このタイプのデータは、主に数学的計算と統計分析に使用されます。さまざまな数学的手法を使用して、簡単に評価および検証できます。
定量的データは一般的に簡潔でクローズエンドです。多くの場合、「いくつ」や「いくら」などの質問をした後、最終的な情報を提供するために使用されます。定量的データの簡単な例には、動物園のトラの数、人の体重、製品の価格、および室内温度が含まれます。
定性的データ
定性的データは統計的ではないため、数値で表すことはできません。それらは半構造化または非構造化することができます。
定量的データとは異なり、定性的データは調査のために開かれています。「なぜ」や「どのように」などの質問に使用できます。定性的研究から得られたデータは、解釈、理論化、仮説の構築、および初期の理解に使用されます。
定性的データの簡単な例には、空の色、名前、匂い、およびアジア系アメリカ人、アフリカ系アメリカ人などの民族性が含まれます。
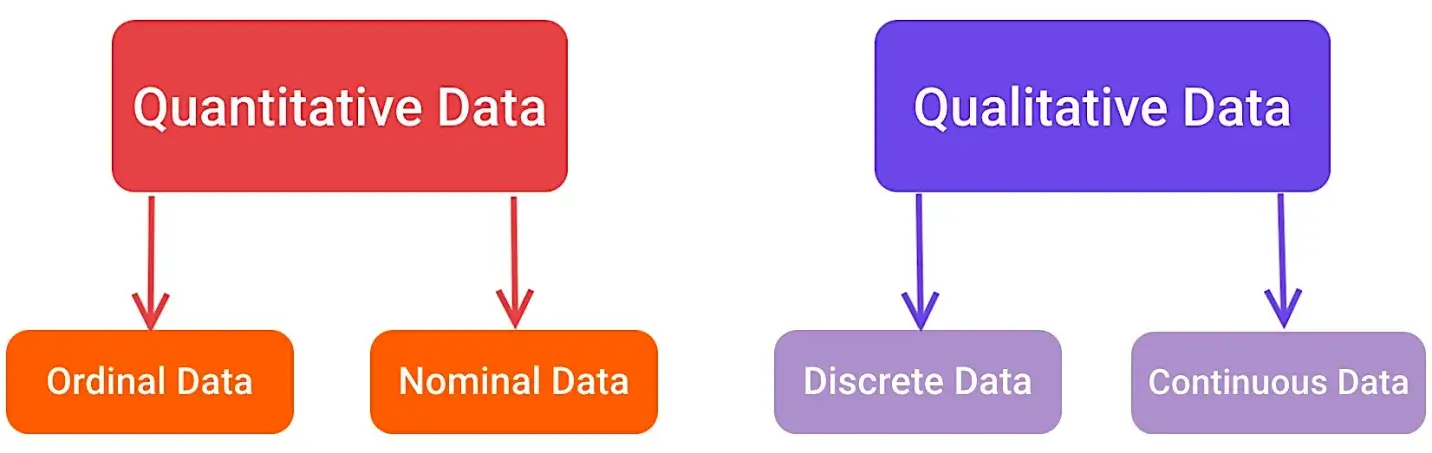
定量的および定性的データは、さらに4つのグループに分類できます。これらの情報の単位をよりよく説明するために、4つの主要なタイプのデータすべてを統計にリストしました。
4.順序データ
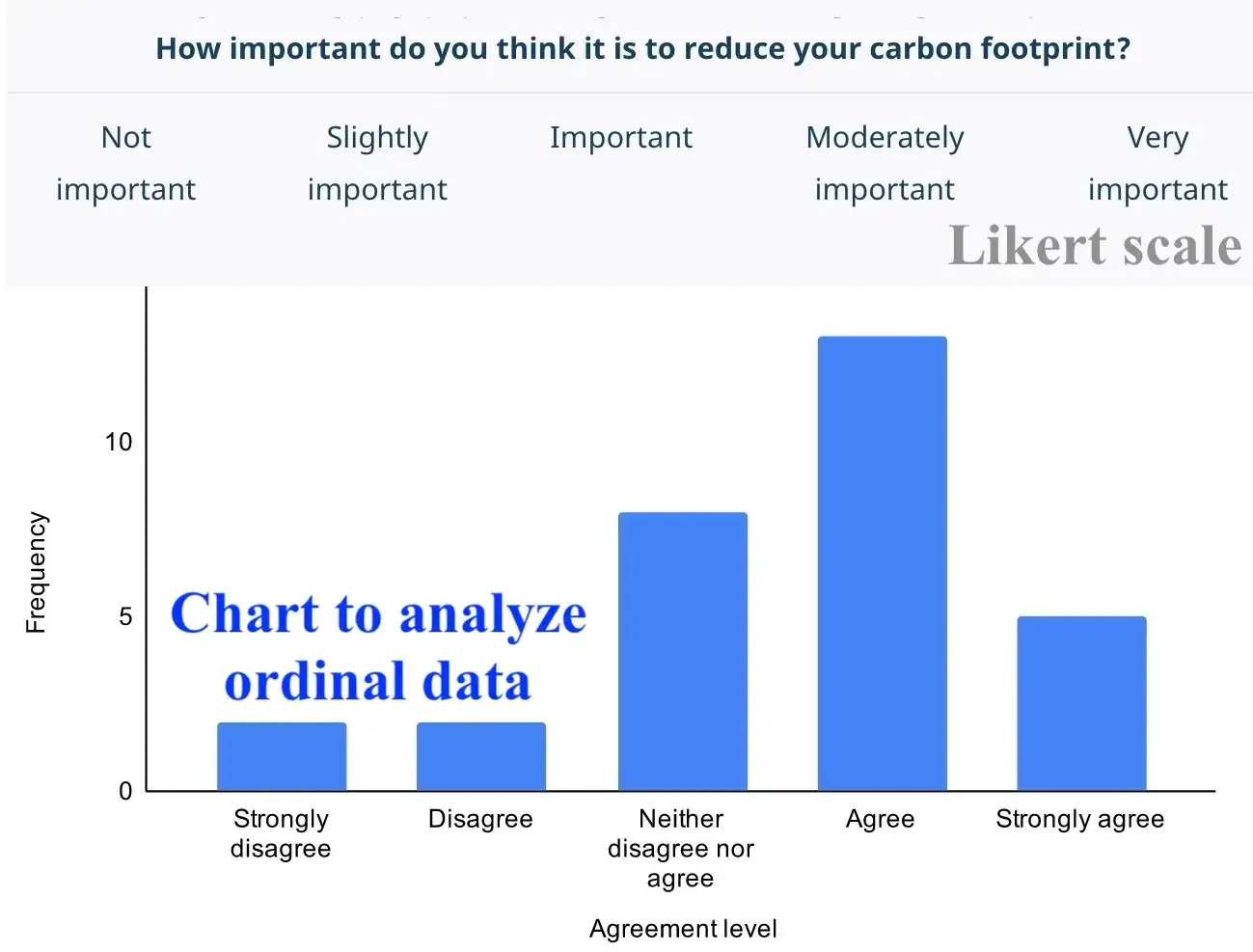
タイプ:定性的データ
順序データは、値が自然な順序に従うカテゴリデータです。データ値の違いはやや無意味であるか、これだけでは判断できません。序数スケールでは、順序は重要ですが、値の違いは重要ではありません。年間3万ドルから15万ドルの収入を得ている100人に、経済的幸福のレベルを評価するように依頼した調査を考えてみましょう。
年間60,000ドルを稼ぐ配達員は、9/10の規模である可能性がありますが、10万ドルを稼ぐ上級理論物理学者は5/10のレートです。これは、スケールが個人の選択に影響され、事前定義された標準によるものではないことを示しています。
順序データの主な特徴
・順序値はシーケンスのみを示します
・順序データに番号を割り当てることができます
・順序値を使用して数学計算を実行することはできません
・序数の差は等しい場合と等しくない場合があります
一般に、順序値は、参加者が選択できる複数の可能な回答を提供するクローズドエンド調査の質問によって評価されます。社会科学では、このタイプのデータを使用して収集されたリッカート尺度3以上のリッカート型の質問で構成されています。
順序値の例には、次のものがあります。
・教育レベル(高校、大学院、大学院、博士号)
・社会経済状況(低所得、中所得、高所得)
・満足度(非常に不幸、不幸、中立、幸福、非常に幸福)
ほとんどの企業は、視覚化ツールを使用して、顧客や従業員から収集された順序データを分析しています。これらのツールは、各行が個別のカテゴリを示すテーブルのデータを表します。一部のデータは、わかりやすい棒グラフやグラフで表示されます。
3.名目データ
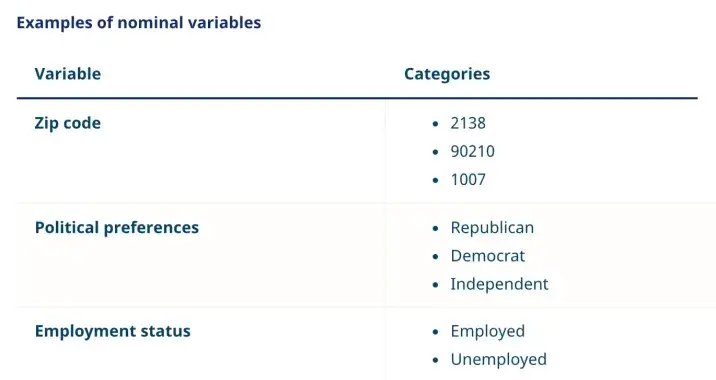 タイプ:定性的データ
タイプ:定性的データ
名目データは、物事の命名またはラベル付けに使用されるノンパラメトリック変数のグループです。通常は「名前付き」データと呼ばれます。
名目スケールは、順序やランク付けがないカテゴリを持つ変数で構成されます。必要に応じて名義変数に数値を割り当てることができますが、順序は任意のままであり、数学的な計算(平均、中央値、標準偏差など)は無意味です。
たとえば、非常に高い、高い、非常に低い、低い、中程度を個別に検討した場合、すべて名目上のデータとなります。それらをスケール上に配置し、特定の順序(非常に高い、高い、中程度、低い、非常に低い)に配置すると、順序データになります。
通常、名目上のデータは、多肢選択式の質問、オープンエンドおよびクローズエンドの質問を介して収集されます。以下は例となります。
・どの市(街)出身なの?(国の都市のドロップダウンリストが続きます)
・あなたの研究分野は何ですか?(空白のテキストボックスが続きます)
名目データの主な特徴
・名目上のデータは定量化できません
・明確な順序を割り当てることはできません
・名目上のデータ収集には評価尺度は含まれていません
・データを順番に並べても、平均値と標準偏差を求めることはできません。
名目データを分析する最も効果的な方法は、変数がグループにクラスター化され、グループごとにパーセンテージまたは頻度を計算できるグループ化手法です。また、棒グラフやバブルチャートを使用するなど、さまざまな視覚的形式で表示することもできます。
名目上のデータは数学演算では処理できませんが、高度な統計手法を使用して詳細に分析できます。たとえば、カイ2乗検定は、与えられた値の推定頻度と観測頻度の間に実質的な違いがあるかどうかを判断します。
2.個別のデータ
 タイプ:定量的データ
タイプ:定量的データ
ディスクリートデータは特定の値のみを取ることができます。これらの値はほとんどが正の整数であり、小さな部分に分割することはできません。たとえば、会社で働く従業員の数は個別のデータです。21.5人または-21人の従業員を数えることはできません。
離散データには無限の数の値が含まれる場合がありますが、それぞれが別個であり、間に他の値はありません。値は、数値(デバイスの数など)またはカテゴリ(男性または女性、赤または青、またはtrueまたはfalseなど)のいずれかです。
離散データの特徴
・ディスクリートデータは特定の値のみを取ることができます
・値を数えることができます
・値を細かく分割することはできません
・データは簡単に視覚化およびデモンストレーションできます
離散値は必ずしも整数である必要はありません。たとえば、靴のサイズが固定値である8.5の場合があります。サイズ8.23の靴は購入できません。
個別データの業界例
洗濯機のテスト(合格または不合格)のデータを収集して、洗濯機を出荷する準備ができているかどうかを確認できます。エンジニアは、次の方法で特定のマシンを分析できます。
・マシンテストが合格または不合格になった回数を確認する
・2日間でさらに20回のテストを行う
結果に基づいて、エンジニアは各ユニットを合格(特定のボルト範囲内で動作可能)または不合格として分類できます。
離散データは、さまざまなグラフで表示できます。棒グラフは、有限値を水平または垂直のバーで明確に表示できるため、離散データを表示するための最も効果的な方法です。度数分布表は、タリーマークと各変数の度数を介して離散値を明確に表すこともできます。
1.連続データ
タイプ:定量的データ
連続データは無限のスケールで測定できます。どんなに小さくても、2つの変数の間で任意の値を取ることができます。たとえば、人の体重は、固定桁だけでなく、(人間の体重の範囲内の)任意の値にすることができます。整数(75)または10進数(74.92)の場合があります。
連続データの主な特徴
・連続データには確率変数が含まれ、整数である場合とそうでない場合があります。
・時間の経過とともに変化し、さまざまな時間間隔でさまざまな値を持つ可能性があります。
・スキューや線グラフなどのデータ分析手法を使用して測定できます。
連続データは、離散データよりもはるかに説明的です—データについて多くのことを教えてくれます。標準偏差(広がり)、平均(中央)を計算し、度数分布曲線(尖度と呼ばれる)のピークの鋭さを測定できます。全体として、記述統計を使用してデータを要約できます。
この詳細レベルは、エンジニア、研究者、メーカーなどにとって最も重要です。さまざまな業界や営利団体が、その膨大なアプリケーションのためにこの種のデータを使用しています。
継続的なデータにより、企業は少量または制限されたサンプルのみを使用して、その数を正確に分析することが容易になります。この情報は、変動の複数の原因に関する詳細な洞察を提供するだけでなく、企業がキー数値と統計が変化している理由を理解するのにも役立ちます。
連続データを効率的に分析するために、ほとんどの企業は回帰分析と呼ばれる方法を利用しています。これは、関心のあるトピックに最も影響を与える変数、これらの変数が相互にどのように影響するか、および無視できる変数を識別するための信頼できる方法です。
よくある質問
コンピュータサイエンスにはいくつのデータ型がありますか?
コンピュータサイエンスとコンピュータプログラミングでは、変数は数値、テキスト、およびその他のさまざまな複雑なタイプのデータを格納するために使用されます。音楽プレーヤーやギャラリーからビデオゲームやソーシャルメディアアプリまで、ほとんどすべてのコンピュータープログラムは、次の基本的なデータ型を使用して、考えられるすべての情報を表します。
・整数:整数に使用
・浮動小数点:分数または小数点に使用されます
・文字:一文字に使用
・文字列:任意の文字(数字、文字、記号)の組み合わせに使用されます
・ブール値:yes / noまたはtrue / falseオプションに使用されます。
構造化データと非構造化データの違いは何ですか?
| 構造化データ | 非構造化データ |
| 明確に定義されており、検索と分析が簡単です | 処理して理解するには、より多くの作業が必要です |
| 多くの場合、データウェアハウスに保存されます | データレイクに保存 |
| 事前定義された形式で存在します | 多くの場合、さまざまなランダム形式で存在します |
| 通常、行と列の形式と非常に明示的なメタデータ要素があります | 厳格なルールや共有フォーマットに準拠していません |
半構造化データと呼ばれる別のカテゴリがあります。名前が示すように、これは構造化データと非構造化データのハイブリッドです。固定スキーマがなく、インテリジェントなデータガバナンス戦略なしでは抽出および処理が難しい重要な洞察が含まれています。
インターバルデータとレシオデータとは何ですか?
間隔データと比率データの両方が、すべてのポイントが互いに等距離に配置されているスケールに沿って測定されます。たとえば、温度計で収集されるデータは間隔データです(マーキングが等距離にあるため)。
間隔スケールでは、変数も負になる可能性があります。算術演算は実行できますが、加算と減算のみに制限されています。
間隔変数とは異なり、比率変数はゼロの特性を持つことができます。零点は、複数の値を測定し、乗算、除算などの数学的操作を実行することができます。年齢、体重、身長、体温(ケルビンで測定)、および売上高は、比率データの例です。
比率変数は、TURF、SWOT、クロス集計、分割表など、最も複雑な分析のいくつかを実行するために使用されます。
変数を分類することが重要なのはなぜですか?
データ変数は、統計計算と分析を行うために分類されます。統計的アルゴリズムは、特に用途が広く機密性の高いデータについて、結果を予測するためのより多くの自由を企業に提供します。
これらのアルゴリズムを使用するには、処理しているデータの種類を知っている必要があります。たとえば、会社で働いている従業員の名前の平均を計算することは意味がありません。連続データとは異なる方法で最適なデータを分析する必要があります。そうしないと、誤った分析になります。