・新アルゴリズムが開発され、問題を解くのに必要な反復回数が大幅に減り、計算を指数関数的に速くなりました
・ソーシャルメディア分析や遺伝子データのクラスタリングなど、大規模なデータセットにおいて、従来の(逐次)アルゴリズムよりもはるかに優れた性能を発揮します
資金を株式に配分してリターンのリスクを最小化したり、ワークフローや従業員の配置を最適にするための問題(すべての実現可能な解から最適解を求める問題)は、アルゴリズムが大きく関わってきます。
これらのアルゴリズムの基本的な動作パターンは、1970年代初頭に確立され、それ以降変更(拡張)されていません。特定の問題は「n」回のステップで順次解いていきます。
ステップ数は問題の大きさ(アルゴリズムにある値を入力する)に依存します。この種類の方法は、通常、計算量が問題になります。各反復から得られる結果は、相対的にアルゴリズムが進むにつれて小さくなっていきます。
もし、アルゴリズムが問題を解くのに何千もの小さなステップを一つ一つ踏まずに、いくつかのステップを省略することができたらどうでしょうか?現在広く使われているアルゴリズムの大規模なセットを指数関数的に速く動作させることができるとしたらどうでしょうか?私たちは、新薬の発見や交通渋滞の回避に役立つアルゴリズムについて話しているのです。
これを可能にするために、ハーバード大学の研究者たちは、問題を解くのに必要な反復回数を大幅に減らすことで、計算を指数関数的に高速化する新しいタイプのアルゴリズム、「ブレイクスルー」を考え出しました。
情報の抽出、広告デザイン、画像処理、計算生物学、ネットワーク解析など、さまざまな分野の幅広い問題に対して計算を高速化することができます。
開発者は、従来は数日から数週間かかっていた大規模計算を数秒で実行することが可能だと考えています。これにより、新たな大規模並列化手法への扉を開き、実用的な要約処理を卓越したスケールで構築することが可能になります。
どのような動きをするのか?
順序アルゴリズムは、実現可能な解の数を一段階ずつ絞り込んでいく仕組みになっています。一方、新しいアルゴリズムでは、異なる方向を並列にサンプリングし、関連性の低い方向を排除して、最も好ましい(値の高い)方向を選択して解決策にたどり着きます。将来の反復で無視されるような値を外していきます。
 適応型サンプリングによる画期的なアルゴリズム | 開発者からの提供
適応型サンプリングによる画期的なアルゴリズム | 開発者からの提供
具体的に言うと、このアルゴリズムはO (log n)の連続ステップが必要で、1/3に近い数値に到達します。並列化した場合、このアルゴリズムは、亜モジュール最大化に対する既存のどの方法よりも速く指数関数的に定数係数の近似値に到達します。
例えば、スターウォーズに似た映画を推薦するというタスクの場合、従来のアルゴリズムでは、スターウォーズと似た属性(アクション、アドベンチャー、ファンタジー)を持つ映画を各ステップで1本ずつ追加していきます。
一方、今回開発されたアルゴリズムは、スターウォーズと全くマッチしないものを削除しながら、ランダムに映画群を抽出します。これによって、スターウォーズに類似した多様な映画(当然、スーパーマンシリーズを10本も推薦することはない)を得ることができます。
このアルゴリズムは、選択するアイテムが十分に揃うまで、各ステップで様々な映画を追加し続けます。この段階的な抽出が、各ステップで結果の精度を上げるカギになります。
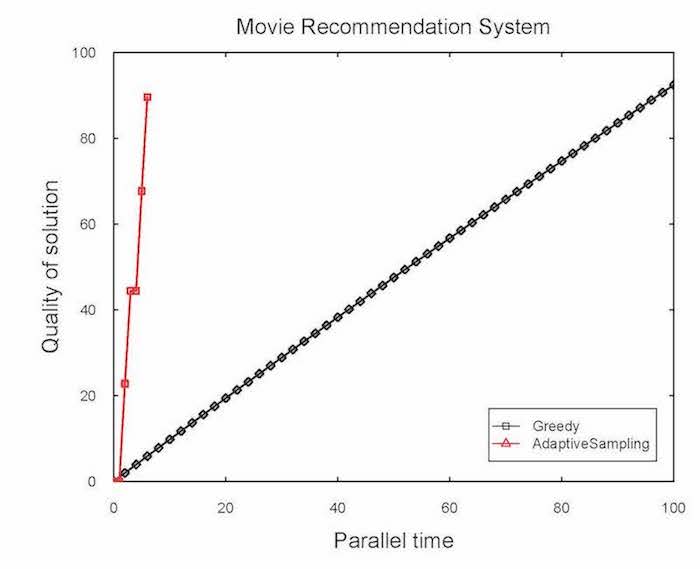 逐次型アルゴリズム(黒)とブレークスルー型アルゴリズム(赤)の問題解決に要するステップ数
逐次型アルゴリズム(黒)とブレークスルー型アルゴリズム(赤)の問題解決に要するステップ数
実験と活用
6,000人のユーザーが4,000本の映画につけた100万件の評価を含む大規模なデータを使って、適応サンプリングアルゴリズムを検証しました。その結果、従来のアルゴリズムに比べ20倍以上の速さで、その人に合った様々な映画を推薦することに成功しました。
また、このアルゴリズムをタクシー配車に適用しました。限られたタクシーで最大数の顧客にサービスを提供するために最適な場所を探すのに使用しました。200万回のタクシー移動に対して、このアルゴリズムは最先端のものより6倍速く動作しました。
ソーシャルメディア分析や遺伝子データの解析など、大規模なデータセットではるかに良い結果を得ることができます。 このほかにも、複数の病気の臨床試験や医療用画像処理用センサーアレイの開発、薬物間の相互作用の検出などにも応用できます。
現在、数百万の画像/動画から深層学習ネットワークを学習するための効果的なデータのサブセットを見つけることが困難な課題となっています。この研究は、価値あるサブセットを迅速に抽出し、大規模なデータ要約を可能にすることができます。