・ソニーが、分散学習によりディープラーニングの最速化を達成。
・適切なバッチサイズと光学的なGPU数を決定するフレームワークを構築した。
・ImageNet/ResNet 50の学習において、3分44秒の高速化を実現。
ディープラーニング【深層学習】は、人間の脳から着想を得たニューラルネットワークを利用する機械学習の一手法です。
deep belief network【深層信念ネットワーク】、deep neural network【深層ニューラルネットワーク】、recurrent neural network【回帰型ニューラルネットワーク】などのアーキテクチャを持ち、音声・画像認識、バイオインフォマティクス、機械翻訳、ソーシャルネットワークフィルタリング、材料検査などの分野で実装されています。
多くの場合、専門家である人間を凌駕する結果を生み出しており、そのためディープラーニングは近年大きな成長を遂げています。一般に深層ニューラルネットワークは、確率的推論や普遍的近似定理の観点から解釈されます。
2018年11月、ソニー株式会社は「AI橋渡しクラウド(ABCI)」と「コアライブラリ:Neural Network Libraries」の組み合わせにより、世界最速のディープラーニング速度を実現したと報告しました。
ディープラーニング技術の精度を高めるために、データサイズと(ネットワークに与える)モデルパラメータは継続的に増加しています。これらの増分は、計算時間を大幅に引き上げています。1回の学習に数週間から数カ月かかることも少なくありません。
人工知能の開発には永遠の試行錯誤が必要であり、この学習時間の短縮は最重要課題の一つになっています。
その仕組みは?
この課題を解決するために、ソニーの研究者は、複数のGPU(画像処理装置)を使った分散学習という一般的な解決策を採用しました。しかし、GPUの数を増やすと、場合によっては学習速度がさらに悪化します。
これは主にバッチサイズ(一度に処理するデータ量)が大きい場合に起こり、文字通り学習が止まってしまいます。遅延の2つ目の理由は、GPU間のデータ転送時間が長いことです。そのため、小さなタスクのためにGPUを増やすと、予想と逆の結果になることがあります。
研究者らは、学習プロセスの現状を分析し、それに応じて適切なバッチサイズと最適なGPU数を決定できる技術「2D-Torus All-Reduceスキーム」を開発しました。ABCIを含む大規模環境での学習にも対応可能です。
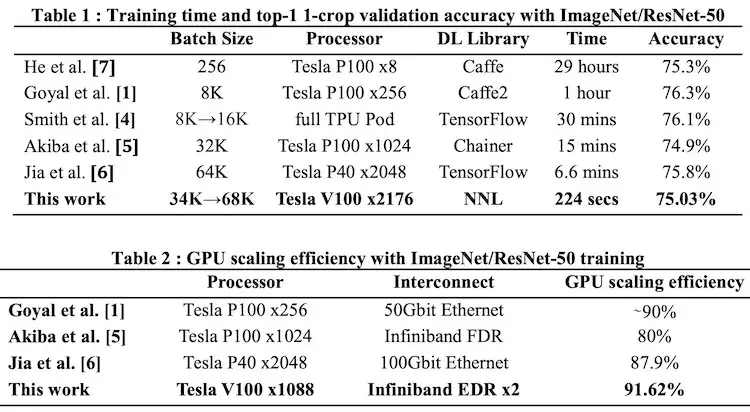
ABCIのために開発されたデータ同期技術により、GPU間の転送速度を向上させることに成功しました。これをNeural Network Librariesに適用し、ABCIの計算資源を利用して学習を行いました。
成果
2,175基のNVIDIA Tesla V100 Tensor Core GPUを使用して、ImageNet/ResNet 50(分散学習速度測定の業界ベンチマーク)をわずか3分44秒、75%の精度で学習する速度新記録を作成しました。これは、これまで報告された中で最速の学習時間です。
これらの成果は、Neural Network Librariesを用いた学習が高速に行えること、同じフレームワークを用いることによって少ない試行錯誤の時間で学習が行えることを示しています。研究者らは今後も研究を続け、AI技術を向上させる新たな手法の開発を目指すとしています。