
















デジタルデータの保存容量は、1980年代から40ヶ月ごとにほぼ2倍ずつ増えています。調査会社IDCは、デジタルデータ量は2025年までに163ゼタバイトに達すると予測しています。
ビッグデータは、このような膨大な量のデータを扱う分野です。従来のデータ処理アプリケーションソフトウェアでは処理しきれない複雑で大容量のデータセットから情報を体系的に抽出、分析することが含まれます。
eラーニング、オンラインショッピング、動画コンテンツ、ソーシャルネットワーキングなどの利用でデータベースがかつてないほど成長を続ける中、膨大な量の情報を管理することが非常に大きな課題となります。その中には、データの転送と保存、クエリ、視覚化、情報の更新などが含まれます。
ビッグデータのリポジトリにはいくつか異なる形式があり、通常は特定要件のために大手テクノロジー企業が開発したものです。あなたが機械学習やテストの目的で巨大なデータベースを必要とするプロジェクトに取り組んでいる場合は、ここでご紹介するデータベースが役に立つでしょう。
特定の環境向けに設計されたオープンソースデータベースとプライベートデータベースの両方をご紹介します。すべてビッグデータ分野の真の主力製品であり、それぞれがビッグデータのマイニングと深い理解を可能にしてくれます。
13位 FlockDB

タイプ:グラフデータベース
FlockDB は隣接リストを格納するためのオープンソースの分散データベースです。高率の追加/更新/削除操作をサポートし、複雑な算術クエリを実行するように設計されています。
他のデータベースとは異なり、FlockDBは解決しようとする問題の数が少なく、情報を必要以上に深く掘り下げることはありません。しかし、幅広いネットワークグラフを使用しているため、Webアプリケーションを効率的に実装できます。
当初、TwitterはFlockDBを使用して、ユーザ(フォロワーとお気に入り)とセカンダリインデックス間のリレーションシップを保存していました。 2010年、Twitter FlockDBには130億以上のエッジが存在し、ピークトラフィックでは秒あたり10万件の読み取りと20万件の書き込みがありました。
12位 Apache CouchDB

タイプ:ドキュメント指向のNoSQLデータベース
CouchDB はWeb を採用するオープンソースデータベースです。JSONドキュメントとしてデータを保存し、HTTP経由でWebブラウザから保存したデータにアクセスできます。結果整合性をもつACID セマンティクスと、レプリケーションを備えた分散アーキテクチャを特徴としています。
JavaScriptを使用して、ドキュメントのクエリ、マージ、変換を行うことができます。データベースと最新のモバイルおよびWebアプリケーションの連携は良好です。 Couch Replication Protocolを使用して、サーバクラスタとWebブラウザ間でデータをシームレスに転送し、高いパフォーマンスと強力な信頼性を提供します。
各データベースには独立したドキュメントのグループがあり、各ドキュメントは独自のデータと自己完結型のスキーマを維持します。 CouchDBはMVCC(マルチバージョン同時実行制御)を採用しており、データベースファイルが書き込み中にロックすることはありません。
11位 OrientDB

OrientDBの特徴
タイプ:NoSQL、マルチモデルデータベース
OrientDB は、Javaで記述されており、ドキュメント、グラフ、キーバリュー、オブジェクトモデルをサポートするオープンソースのマルチモデルデータベースです。柔軟なドキュメントと強力なグラフが1つのスケーラブルなデータベースに統合された最初のNoSQL DBMSです。
データベースは非常に高速になるように設計されています。コモディティハードウェア上で毎秒最大220,000件のレコードを保存できます。ユーザは、数千件のレコードを数ミリ秒でトラバースできます。
複数マシンで効率よくスケールアウトできます。1台のサーバまたは複数のノード上で 19兆ペタバイトのデータ最大容量に対して278件のレコードを格納できます。 OrientDBは、スキーマレス、スキーマフル、またはミックスモードをサポートし、ユーザーとロールに基づく強力なセキュリティ プロファイリング システムを備えています。
10位 Wikipedia および Stackoverflow Data


StackExchangeのファイル
タイプ:SQL
プロジェクトで大量のテキストコンテンツが必要な場合、Wikipedia は利用可能なすべての記事が含まれる無料のデータベースを提供します。データベースを個人のプロジェクトで使用し、Quarryを使用してブラウザからSQLクエリを実行することも可能です。
すべてのテキストコンテンツは、GNU Free Documentation LicenseおよびCreativeCommonsLicenceからマルチライセンス供与されています。音声、動画、および写真は、さまざまな条件で利用可能です。
Stack Exchange Network上のすべてのユーザー投稿コンテンツの匿名化されたダンプは、インターネットアーカイブでも入手可能です。すべてのサイトには、zip形式のXMLファイルを含む個別アーカイブがあります。各アーカイブには、ユーザ、投稿、コメント、投稿リンク、投票、および投稿履歴が含まれます。
9位 Yahoo Webscope Program

タイプ:プロジェクトごとにデータセットの形式が異なります
Yahoo Webscope Program は、学術研究者向けのイニシアチブであり、認定大学の教職員、研究員、学生が非営利目的で使用するための、科学的に有用なさまざまなデータセットが含まれています。
このプログラムは、6つのカテゴリのデータセットを提供します。
・コンピューティングシステムデータ
・言語データ
・競合データ
・グラフとソーシャルデータ
・評価と分類データ
・広告と市場データ
各データベースは、Yahooのプライバシーとデータ保護規格に準拠するように評価されています。
8位 Neo4j

タイプ:グラフデータベース
Neo4j はデータとデータリレーションシップの両方を活用するためにゼロから作成されたネイティブなグラフデータベースです。データを行と列に入力する従来のデータベースとは異なり、Neo4jは、データ間の関係が格納されるため柔軟な構造を持っています。
すべてがノード、エッジ、または属性の形式で保存されます。個々のノードとエッジは、n個の属性を持つことができます。絞り込み検索を容易にするために、ノードとエッジの両方にラベルを付けることができます。データ間のコネクションは保存され、クエリ時に計算されます。
Neo4jはJavaで実装されていますが、Cypher(宣言型グラフ)クエリ言語を介して他の言語で記述されたプログラムからアクセスできます。Cypherクエリは、大規模なSQL JOINよりも単純で記述が簡単です。このデータベースにはテーブルがないため、JOINについて心配する必要はありません。
7位 Riak

Riakの使用例
タイプ:NoSQL キーバリュー型 データストア
Riak はスケーラビリティ、簡単な操作、フォールトトレランス、高可用性を提供するオープンソースの分散データベースです。エンタープライズ、クラウド、Web、およびモバイルプラットフォームで利用できます。
Riak KV(分散NoSQLデータベース)とRiak TS(IoTおよび時系列データ用に最適化されたもの)の2つのバージョンがあります。どちらも、Redis Caching、Apache Solr、Apache Spark、ApacheMesosなどのさまざまなビッグデータ技術と統合されています。
ブラウザから直接呼び出し可能な大きなファイル用のプライベートクラウドストレージが必要な場合、または単純なRESTインターフェイスを介してデータベースをテストする場合は、Riakを試してみるのもいいでしょう。
現在、The Weather Channel、Comcast、Best Buy、GitHub、AT&T、UK National Health Servicesなど、多くの企業で使用されています。
6位 RethinkDB
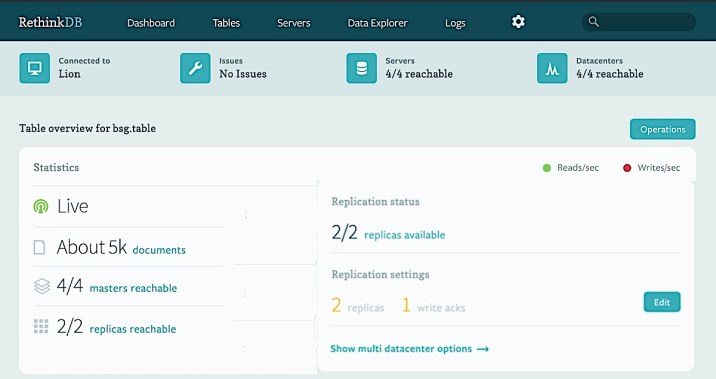
タイプ:ドキュメント指向データベース
Rethink はリアルタイムWeb用の無料のオープンソースデータベースです。動的スキーマを使用してJSONドキュメントを保存し、更新されたクエリ結果をリアルタイムでWebアプリケーションに継続的にプッシュします。そのため、スケーラブルなリアルタイムアプリの開発に必要な労力と時間が大幅に削減されます。
Rethinkは柔軟なクエリ言語、モニタリングAPI、直感的な操作を提供しており、設定と学習は容易です。Amazon AWSおよびCompose.ioクラウドで利用可能ですが、制限付きで独自のインフラストラクチャに構築することもできます。
Rethink は、何百ものコンサルティング企業、テクノロジースタートアップ、および一部のFortune500企業で採用されています。たとえば、Workshape.ioとPlatziは、RethinkDBを使用してリアルタイム分析を強化しています。 Narrative Clipは、デバイスが接続されたクラウドインフラストラクチャに、Mediaflyはリアクティブモバイルアプリやウェブアプリに使用しています。
5位 ArangoDB

ArangoDBクエリに使用されている3つの特徴: マルチモデル、Join、トランザクション
タイプ:マルチモデルデータベースシステム
ArangoDBは、ドキュメント、グラフ、検索をネイティブにサポートするオープンソースのスケーラブルなデータベースです。サポートされているすべてのデータモデルとアクセスパターンをクエリにマージできるため、最大限の柔軟性が得られます。
ArangoDBはNoSQLデータベースシステムですが、ArangoDBクエリ言語は多くの点でSQLに似ています。地理空間クエリおよびドキュメント(ノード)とエッジの両方でCRUD操作 (作成、読取り、更新、削除)をサポートします。
ArangoDBのその他の機能には、マルチスレッド機能、コマンドライン、Webインターフェイスツール、大規模(RAMよりも大きい)データセットを処理するためのさまざまなストレージエンジンが含まれます。
4位 Apache HBase

HBaseの特徴
タイプ:非リレーショナル分散データベース
HBaseはJavaで記述され、GoogleのBigtableをモデルにしています。 Apache Hadoopプロジェクトの一部として開発され、数十億行、数百万列の情報を含む大量の構造化データへの迅速なランダムアクセスを提供するように設計されています。
Hadoop分散ファイルシステム(HDFS)上で実行され、大量のスパースデータを耐障害性の高い方法で格納できます。この種のデータベースは、高スループットと入出力時の低遅延を保ちつつ、高速な読み取り、書き込み操作を必要とする動作の重いアプリケーションに適しています。
また、SQLレイヤーとJava Database Connectivityドライバーを備えており、幅広いビジネスインテリジェンスおよび分析プログラムと統合できます。
Facebook、Alibaba Group、Netflix、Spotify、Imgur、Adobe、Airbnb、Yahoo、Pinterest、Xiaomiは、HBaseを使用している、または使用したことのある主要企業の一部です。
3位 Apache Cassandra

タイプ:NoSQLデータベース
2008年に最初にFacebookによって開発された Apache Cassandra は、オープンソース、ワイドカラムストア型のNoSQL分散データベースです。複数のコモディティサーバにまたがる膨大な量のデータを処理し、単一障害点のない継続的な可用性(ダウンタイムなし)を提供するように設計されています。
Cassandraはフォールトトレランスのために、複数のノードへの自動データレプリケーションを提供しています。障害が発生したノードをほとんどダウンタイムなしで置き換え、すべてのユーザーに低遅延で操作を提供します。
Cassandraは、Java ManagementExtensionsを介して監視および管理できます。たとえば、NodetoolはCassandraクラスタを効率的に処理できます。クライアントはノードの解凍、リングへのノードの追加、およびノードのドレイン(解放)を行うことができます。
CassandraはFortune100の30%以上の企業で使用されています。大規模な実稼働展開の例は次のようになっています。
・Appleは、100,000ノードで10ペタバイト以上のデータをCassandraで運用
・Netflixは、2,500ノードで420テラバイト以上のデータを運用し、1日あたり1兆件のリクエストを処理
・Soundcloudは、Cassandraを使用してユーザーのダッシュボードを格納
・Netflixは、ストリーミングサービスのバックエンドデータベースとしてCassandraを使用
全般的に、Cassandraは従来、最も厳しい要件のユースケースに耐える高度で効率的なデータベースとして知られています。
2位 Oracle NoSQL Database

タイプ:キーバリュー型分散データベース
Oracle NoSQL Databaseは、水平方向のスケーラビリティ、データの監視、操作、および単純な管理のためのトランザクション セマンティクスを提供します。テーブルと事前定義されたデータスキーマに依存するリレーショナルな構造化クエリ言語(SQL)には準拠していません。
2018年、オラクル社は、柔軟なデータモデル、低遅延応答、動的なワークロードの柔軟なスケーリングを必要とする高度なアプリケーション向けに、Oracle Autonomous NoSQL Database Cloudという名称でマネージド クラウド サービスを開始しました。
Enterprise Manager、BerkeleyDB、Fusion Middleware、Communication Elastic Charging Engineなどのさまざまなオラクル製品と統合できます。Oracle NoSQL DatabaseはPython、Java、Node.js C、C#、およびREST APIをサポートしているため、ユーザはバックエンドのソフトウェアやハードウェア インフラストラクチャについて心配することなくアプリケーションの開発に集中できます。
このデータベースの代表的なユースケースには、モバイルアプリケーション、オンライン広告、ソーシャルネットワーク、オンラインゲーム、360度顧客ビュー、異常検出などがあります。オラクル社によれば、クラウドサービスは10ミリ秒未満の応答時間を実現します。
1位 MongoDB
タイプ:ドキュメント指向データベース
MongoDBはC++で記述されたオープンソースのNoSQLデータベースです。データをJSONドキュメントとして保存し、従来の行/列モデルよりも強力で表現力豊かです。
リッチJSONドキュメントの利点
・配列とネストされたオブジェクトを値としてサポートします。
・柔軟で動的なスキーマを有効にします。
・クエリ自体がJSON形式であるため、簡単に作成できます。 SQLクエリを動的に作成するために文字列を連結する必要はありません。
MongoDBには、代表的なプログラミング言語と開発環境用の公式ドライバがほぼすべてそろっています。あまり知られていないフレームワーク向けの、コミュニティでサポートされている(非公式の)ドライバーもいくつかあります。
MongoDBは、最新のアプリケーションとクラウド時代に向けて開発されました。 Google Cloud、Azure、AWSでフルマネージドサービスとして利用できます。
MongoDBはIBM、Cisco、HSBC、Uber、Bosh、eBay、Coinbase、Codeacademyなど多数の大手企業で使用されています。





