ボードゲーム(チェスなど)は、人工知能の歴史において広く研究されている分野です。チューリング、バベッジ、フォン・ノイマン、シャノンといった先駆者たちは、チェスゲームを分析し、プレイするための理論、アルゴリズム、ハードウエアを開発しました。
そしてここ数年、囲碁や将棋(日本のチェス)のようなもっと複雑なゲームで、人間を凌駕する同様のプログラムを目にするようになりました。
グーグルのDeepmindは、ボードゲームで人間に勝つことに関して驚異的な実績があります。2015年、彼らのプロジェクトAlphaGoは、コンピューター囲碁プログラムとして初めて人間(プロの囲碁棋士)に勝ちました。そして今回、彼らはチェスのゲームを自ら学習し、人間や他のコンピュータープログラム(StockfishとDeep Blueを含む)を4時間近くで打ち負かすことができるAlphaGoプログラムを開発したのです。
従来の(ボードゲームの)AIプログラムは、高度に定義化されており、人間が介入しないと定義されていない問題を解決することはできません。一方、AlphaZeroプログラムは、いくつかの困難な領域で超人的な性能を達成することができます。
ゲームルール以外の予備知識を持たず、ランダムプレイからスタートしたAlphaZeroは、チェス、将棋、囲碁のゲームで24時間以内に超人的なプレイレベルを達成し、世界最高のプログラムに勝ちました。どのようにして、そしてどのような結果を得たのでしょうか?その秘密を探っていきましょう。
方法論
2017年10月、Deepmindは、同社のAlphaGo Zeroアルゴリズムが、深層畳み込みニューラルネットワークを用いて、強化学習のみによって学習させることで超人的なパフォーマンスを達成したと発表しました。エンジニアは同じ方法でAlphaZeroと呼ばれる汎用アルゴリズムを構築し、従来のゲームプレイアルゴリズムで使用されていたドメイン固有の増強と手入力された知識を、ディープニューラルネットワークとタブララサ強化学習アルゴリズムに置き換えました。
AlphaZeroは、アルファベータ探索ではなく、汎用のMCTS(Monte-Carlo Tree Search モンテカルロ木探索)アルゴリズムを使用しています。 これは、自分自身と対戦することによって、推定値と手の確率を学習し、学習された情報を使って探索を行うものです。
AlphaGo Zero アルゴリズムの特徴
AlphaGo Zeroアルゴリズムは、勝敗から勝率を推定し、最適化します。一方、AlphaZeroは、引き分けやその他の可能性のある結果を考慮して、期待される結果を推定し、最適化します。囲碁のゲームルールは、順番や置き方が変わることがない。これを、AlphaGoとその進化型であるAlphaGo Zeroにおいて、2つの方法で非常にうまく利用しています。
・各ポジションに対して8つの対称性を作成し、学習データを補強します。
・MCTSアルゴリズムでは、ニューラルネットワークで計算する前に、ランダムに選択された反射や回転で位置を変換し、異なるバイアスで計算が平均化されるようにします。
チェスや将棋の場合、ルールが非対称であり、一般的な対称的なデータを仮定することはできません。AlphaZeroでは、MCTSの際に学習データの補強や盤面位置の変換を行いません。
AlphaGo Zeroは、過去の反復処理で最も優れたプレイヤーを使用して、自己対戦ゲームを生成します。各反復が完了すると、新しいプレーヤーのパフォーマンスが最高のプレーヤーに対して評価されます。55%の差で勝利した場合、ベストプレーヤーを変え、新しいプレーヤーとの自己対戦が生成されます。ただし、AlphaZeroでは、反復が完了するまで休止するのではなく、1つのニューラルネットワークを維持(継続的に更新)しています。
AlphaZero最適化トレーニング
AlphaZeroは、ゲームの一部のみ最適化するのではなく、ゲーム全体にハイパーパラメータを使用しています。探索を確実にするために、ゲームの正当な手の数に比例してスケールされるノイズファクターを統合しています。
AlphaGo Zeroと同様に、各ゲームの基本ルールに基づき、盤面の状態は空間平面で、アクションは空間平面または平面ベクトルで符号化されます。
開発者はAlphaZeroをチェス、将棋、囲碁に適用しました。3つのゲームとも同じネットワークアーキテクチャ、ハイパーパラメータ、設定が使用されました。アルゴリズムの個々のインスタンスは、各ゲームごとに学習されます。ランダムに初期化されたパラメータから始まり、70万ステップの学習が行われました。自己対戦ゲームの構築には5000個の第1世代Tensor Processing Unitが、ニューラルネットワークの学習には64個の第2世代Tensor Processing Unitが使用されました。
結果



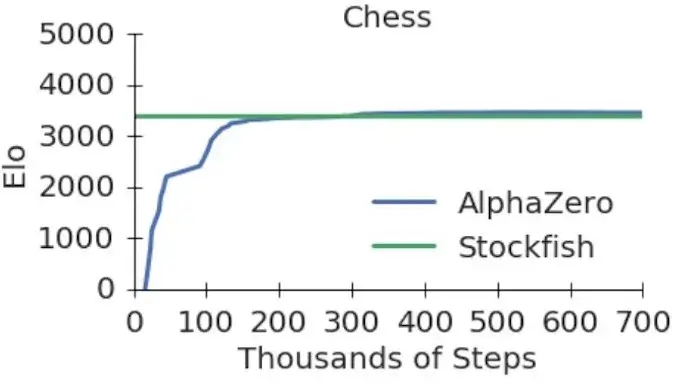
図にあるように、AlphaZeroはチェスで30万歩(4時間後)、Elmoは11万歩(2時間以内)、AlphaGo Leeは16万5千歩(8時間後)でStockfishを上回りました。戦い方を完全学習済み(3日間学習)のAlphaZeroをAlphaGo Zero、Elmo、Stockfishと対戦させ、1手1分で100試合行いました。その結果は非常に素晴らしいものでした(下表に記載)。

AlphaGo ZeroとAlphaZeroは4つのTensor Processing Unitを搭載した1台のマシンを使い、ElmoとStockfishは64スレッドと1GBのハッシュサイズを使って最高のパフォーマンスを発揮しました。AlphaZeroは、ElmoとStockfishに8敗しかせず、完勝しました。
Googleの開発者は、AlphaZeroにおけるMCTS検索の性能も検証しています。1秒間に将棋で4万、チェスで8万のポジションを検索するのに対して、Elmoでは35,000,000、Stockfishでは70,000,000検索しました。AlphaZeroは、ディープニューラルネットワークを利用して、より有望な選択肢を選ぶ、より人間に近いアプローチと言えます。
AlphaZeroはまだ始まったばかりですが、その目的に向かって重要な一歩を踏み出したと言えます。同様のアプローチが、タンパク質の折り畳み、新素材の発見、エネルギー消費の削減など、他の構造的問題にも適用できれば、我々の未来にいい影響を与える可能性を秘めています。