・低消費電力のPCやノートPCに接続して大規模なグラフを処理できる新しいデバイスが設計された。
・最大で40億ノード、1280億エッジの巨大グラフを処理することができる。
・技術系企業では、このデバイスを使ってサーバーの台数を減らすことで、エネルギー使用量を削減することができる。
コンピュータサイエンスにおいて、グラフはノード【「結び目」の意味で、構造体における個々の要素】とエッジ(ノード間を結ぶ線)からなる構造で、複雑なデータ構造の重みを効率的にマッピングするために使用されます。データ整理、通信網の表現、計算フローなど、幅広く応用されています。
たとえば、グラフはソーシャルメディアにおける友人とのつながり、ウェブページのランキング、Googleマップでの経路検索、eコマースサイトでのおすすめ商品の表示、脳内のニューロン構造のプロットなどに利用されています。
大規模なグラフは数十億の頂点と辺で構成され、メモリ上に数テラバイトの容量を占有します。通常、これらは、電力を消費する複数のサーバーにまたがるDRAM(ダイナミック・ランダム・アクセス・メモリ【読み書き用の半導体メモリの一種】)で実行されます。
今回、MIT【マサチューセッツ工科大学】のエンジニアたちが、パソコンやノートパソコンで巨大なグラフを処理できるデバイスを設計しました。このデバイスには、フラッシュチップ(大規模な業務用ストレージシステムやスマートフォンなどの小型計算機で一般的)の配列と、計算アクセラレータが搭載されています。
DRAMはグラフデータ構造の処理においてフラッシュストレージより高速ではありますが、非常に高価です。そこで、フラッシュチップの性能を向上させるために、計算アクセラレータを設計し、グラフデータへのアクセス要求を順次ソートする新しいアルゴリズムを開発しました。
このアルゴリズムでは、いくつかのリクエストを組み合わせることで、ソートのオーバーヘッド(計算時間、帯域幅、メモリ)を減少させます。フラッシュストレージは、このような順番に並べられた要求を簡単かつ高速に処理することができます。
その仕組みは?
従来のシステムは、グラフをDRAMで処理するため、コストが高く、消費電力も大きいものでした。コストを下げるために、一部のシステムはデータの一部をフラッシュストレージ(効率が悪く、速度も遅い)にオフロードしていますが、それでもかなりの大きさのDRAMが必要です。
今回の新デバイスは、すべてのダイレクトアクセスのリクエストを識別子で順番に並べる「ソート・リデュース」アルゴリズムを搭載しています。この識別子は、たとえば、頂点Xのすべての更新、頂点Yのすべての更新、頂点Zの更新、といったように、グループ化されたリクエスト先を表しています。フラッシュは、これらの何千ものチャンク【ヘッダーを持つ、ひとまとまりのデータ】(KBサイズ)に一度にアクセスすることが可能です。

黒色のフラッシュチップ8個と正方形のアクセラレータ1個(左側)を搭載したデバイス
画像出典:MITコンピュータ科学・人工知能研究所
また、このアルゴリズムでは、データを最小のクラスタに同時結合することで、より多くの帯域幅と計算能力を節約しています。たとえば、X1とX2がX3になるように、類似した識別子を検出すると、それらを加算して1つのデータパケットを作成します。
このアルゴリズムは、可能な限り小さなサイズのパケットを生成するまで続けられます。これにより、ノードへの重複したアクセス要求がなくなり、開発者はフラッシュストレージで更新が必要な総データを最大90%削減することができます。
このアルゴリズムはホストPCのリソースを大量に消費するため、エンジニアはカスタムアクセラレータをデバイスに組み込み、フラッシュストレージとホストの間のインターフェイスとして機能させました。ソート・リデュースアルゴリズムに必要なすべての計算を実行するため、ホストは低消費電力のノートPCやPCで、ソートされたデータを管理しながら他の小さな計算を実行することができます。
性能試験
Web Data Commonsのハイパーリンクグラフ(ノード数35億、エッジ数1280億)など、様々な巨大グラフに対してテストを行いました。
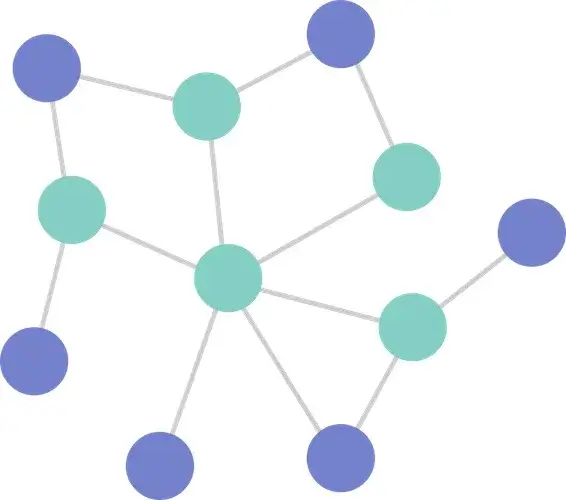
ノード数11、エッジ数13の小さなグラフ
こういったグラフを処理するために、従来のシステムでは128GBのDRAMが必要で、全体で数千ドルのコストがかかっていました。一方、新システムでは、PCに接続した2つのデバイスで同じ処理を行うことができます。1GBのDRAMと1TBのフラッシュストレージで構成されています。
複数のデバイスを接続すれば、従来のシステムでは処理できなかった40億ノード、1280億エッジの巨大グラフも、128GBのDRAMサーバーで処理できるようになります。
つまり、このデバイスは性能を向上させながら、コストと消費電力を削減することができるのです。IBM、Google、Microsoftなどの技術大手は、このデバイスを使って、より少ないサーバーでグラフを処理することで、エネルギーフットプリントを減少させることができます。
研究者によると、このシステムは、中間更新リストをサーバー間で分割することで、簡単に水平方向に拡張してクラスタ上で動作させることができるそうです。さらに、GPU(グラフィックス・プロセッシング・ユニット)でもうまく動作するはずで、並べ替えや結合作業を高速化し、フラッシュの帯域幅を有効に活用することができるとしています。