・AIが作成したコンテンツを検出できる新しい統計手法。
・文章内の誤りフラグを立てるのではなく、予測可能性の高い文章を特定することで、文章の誤りを発見する。
この10年間ほどで、自然言語処理【人間の言語(自然言語)を機械で処理し、内容を抽出すること】のコミュニティは、ますます大規模でスマートな言語モデルの成長を目の当たりにしてきました。
AI【人工知能】やディープニューラルネットワークが人間の自然な言語を備える現代において、ハーバード大学とIBMリサーチの研究者たちは、コンピュータで生成された文章を検出する統計的方法を開発しました。
彼らは、人間の自然な言語と、人間の音声から機械が生成した文章を区別するための対話型ツール(一般公開されている)を構築してきました。その目的は、人々がより多くの情報を得ることで、何が偽物で何が本物なのか、十分な情報に基づいて判断できるようにすることです。
AIモデルは、通常、何百万もの文章(世界中のWebから取得したもの)を使って学習されます。AIモデルは、人間の言語を模倣するために、ある単語に最も頻繁に続いて使われる単語を予測します。例えば、「You」という単語には、「were」、「have」、「are」という単語が続く可能性が統計的に最も高いとされています。
研究者はこの方法論を使って、文章内の誤りにフラグを立てるのではなく、予測可能性の高い文章を検出するツールを構築しました。これにより、AIと人間の両方が協力して、機械が生成した言語を特定することができます。
どのように機能するのか?
GLTR(Giant Language model Test Roomの略)と名付けられたこの新しい技術は、Webサイトから得た約4,500万件の文章で訓練されたモデルに基づいています。GLTRは、公開されている最大級のモデルである「GPT-2」を利用することができます。
したがって、GPT-2が各位置で何を予測したかを観察することができ(あらゆる文章入力に対して)、GPT-2や他の多くのモデルに対して効率的なパフォーマンスを発揮することができます。
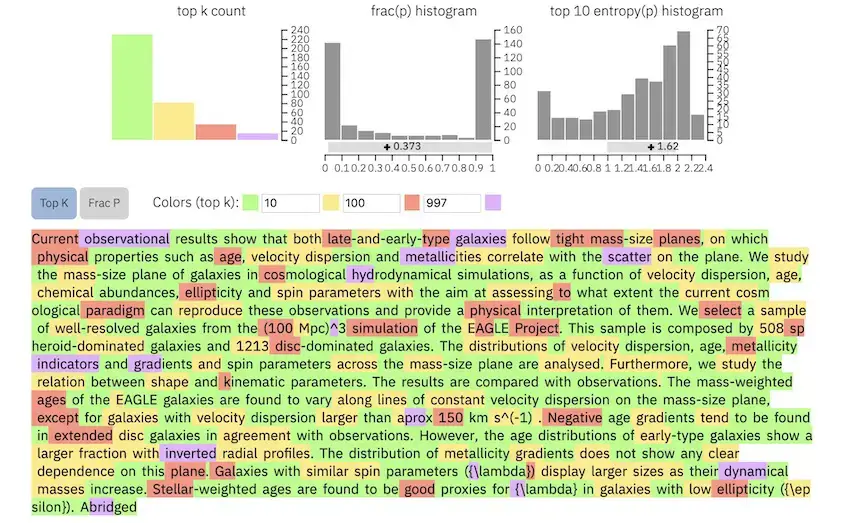
GLTRは、自動生成された文章を識別するための視覚的なフォレンジックツールを代表するものです。文章全体の情報を集約した3種類のヒストグラムを表示します。
ひとつの段落をツールボックスに入力すると、すべての単語が4つの色でハイライトされ、それぞれの色は、その後の文脈におけるその単語の予測可能性を示しています。紫色は段落内で予測不可能な単語、赤色はやや予測可能な単語、黄色は中程度に予測可能な単語、緑色は予測可能性の高い単語を示します。
機械で生成された段落は、次のようになります:

1番目のヒストグラムは、各カテゴリーの単語がこの段落に何個出現するかを示しています。2番目のヒストグラムは、最も高い確率で予測された単語と、それに続く単語の確率の比率を表しています。3番目のヒストグラムは、予測エントロピー【ある出来事の起こりにくさの関数として表される情報量】の分布を表しています。
もちろん、人間が書いた文章、特に研究論文や学術的な文章であれば、不確実性は高くなります。研究論文(EAGLE銀河に関するもの)の要旨は、次のように、予測可能性の低いハイライト色が多くなります:
研究チームは、コンピュータサイエンス科の卒業生たちを対象に、この新しいツールのテストを行いました。その結果、卒業生はコンピュータで生成されたパラグラフの50%を検出することができましたが、このツールを使った場合は72%を検出することができました。この割合は、システムの学習によってさらに向上する可能性があります。