
















・TPUは、ニューラルネットワークの機械学習用に特別に設計されたAIアクセラレータチップです。
・TPUはTensorFlowを含むディープラーニングタスクに適していますが、GPUはより汎用的で柔軟な超並列プロセッサです。
人工知能(AI)の一部門である機械学習は、技術分野の昨今の流行語です。驚異的な速さで機械学習の関連度と重要度が高まりつつありますが、いまだに従来のプロセッサは、トレーニングであっても、はたまたニューラルネットワーク処理であっても、効率的に機械学習を処理することができていません。
いくつかのメーカーは、高速グラフィックス処理用の高度な並列アーキテクチャを備えたGPUを構築しており、CPUよりも強力ですが、若干劣っています。
この問題に対処するために、Googleは、ニューラルネットワークの機械学習に使用されるAIアクセラレータのアプリケーション固有の集積回路を開発しました。デバイスはTensorFlow Framework用に特別に設計されているため、Tensor Processing Unit(TPU)と名付けられました。
知らない人のために説明すると、TensorFlowはデータフロープログラミングとさまざまな機械学習タスクのためのオープンソースライブラリです。 Googleによって開発され、MacOS、Windows、Linuxディストリビューションで利用できるようになりました。近年、GitHubで最も脚光を浴びるAIフレームワークの1つになりました。
GPUの特徴とTPUとの違い
GPUは元々、画面上のグラフィックスを回転するために必要な大きな計算を処理し、ゲームアプリケーションで画面をレンダリングするなど、他のタイプのグラフィカルタスクを高速化するために構築されました。その目的は、CPUの過剰な負担を軽減し、他のプロセスを使用できるようにすることでした。
2007年、NVIDIAはCUDAと呼ばれる並列コンピューティングプラットフォームとアプリケーションプログラミングインターフェイスを開発しました。これにより、開発者はほとんどすべてのタイプのベクトル、スカラー、または行列の乗算と加算にGPUを使用できます。
従来のCPUには1〜16個のコアがありますが、GPUには数百個あります。 TPUとGPUは同じテクノロジーです。適切なコンパイラのサポートがあれば、両者は同じ計算タスクを達成できます。

現在のシナリオでは、GPUは従来のプロセッサとして使用でき、ニューラルネットワーク操作を効率的に実行するようにプログラムできます。一方、TPUは完全に汎用的なプロセッサではありません。サポート(コンパイラなど)がまだ利用できないため、TPUはTensorFlowモデル以外のものをほとんど実行できません。
TPUはクラウドで利用可能
Googleは、機械学習モデルをトレーニングおよび実行するための独自の「クラウドTPU」を提供しています。クラウドTPU v2は、オンデマンドおよびプリエンプティブリソースの使用に対して課金されます。カスタム高速ネットワークは、180ペタフロップスのパフォーマンスと64 GBの高帯域幅メモリを提供します。

Googleの価格情報によると、各TPUの料金は1時間あたり4.50ドル(オンデマンド)です。製品ページに複数のモデルが掲載されています。バージョンごとに異なるクロック速度とメモリサイズがあります。
TPUのアーキテクチャ
ユーザーは、TensorFlowを使用してTPUアクセラレータハードウェアで機械学習ワークロードを実行できます。 Cloud TPUは、プログラマーがGPU、TPU、およびCPUを使用できるTensorFlow計算クラスターを開発するのに役立ちます。また、ユーザーは、高水準のTensorflow APIを使用して、Cloud TPUハードウェア上で複製モデルを簡単に実行できます。
TPUはPCIインターフェースを介して、Googleクラウドマシンに接続されます。こうしてNVIDIAがグラフィカルな拡張カードを追加したことで、ゲーマーがPCのパフォーマンスを向上させることができます。
TPUチップに統合されたハードウェアサポートにより、広範囲のディープラーニングタスクにわたって線形のパフォーマンススケーリングが可能になります。
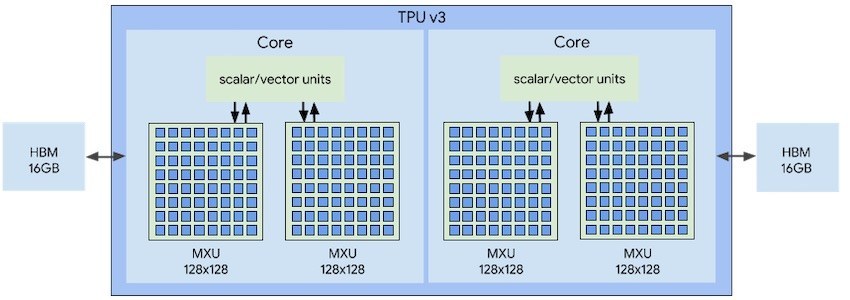
Cloud TPUハードウェアは4つの独立したチップで構成され、各チップにはTensorコアと呼ばれる計算コアが2つ含まれています。 Tensorコアは、ベクトル、スカラー、マトリックスユニット(MXU)、および16 GBのオンチップメモリ(HBM)で構成されています。
8つのコアのそれぞれが、ユーザータスクを独立して実行できますが、高帯域幅メモリにより、チップは互いに直接通信できます。
TPUの使用による利点
GoogleのTPUを使用すると、多くの点で有益です。いくつかの利点を挙げてみました。
1、線形代数計算のパフォーマンスを大幅に改善できます。
2、大規模で複雑な機械学習モデルをトレーニングしながら、精度を得るまでの時間を最小限に抑えます。
3、コードを記述する必要なく、複数のマシンで計算をスケーリングできます。
4、新しいTPUバージョンは、以前は他のハードウェアプラットフォームで数週間かかっていたモデルを数時間でトレーニングできます。
TPUの利用に適当、不適当な条件
TPUは特定のタスクに対してのみ最適化されています。したがって、場合によっては、TPUよりもGPUを優先して使用する必要があります。以下にその条件をまとめています。
1、TensorFlowに記述されていないモデル。
2、TensorFlow opsを備えたモデルは、GoogleのクラウドTPUでは利用できません。
3、ソースを変更するのが難しすぎる、またはソースがまったく存在しないモデル。
4、CPUで少なくとも部分的に実行する必要があるカスタムTensorFlow操作を含むモデル。
CPUで少なくとも部分的に実行する必要があるカスタムTensorFlow操作を含むモデル。
以下は、GPUよりもTPUを優先すべき事例です。
1、カスタムTensorFlow操作を持たないモデル。
2、多くの行列計算を含むモデル。
3、巨大な効果的なバッチサイズを持つ大規模モデル。
4、数か月間のトレーニングを要するモデル。
これまでの主な業績
TPUは、Google DeepMindが開発したAlphaGoやAlphaZeroシステムなど、いくつかのGoogle製品や新しい開発品で使用されています。 AlphaZeroは、碁、将棋、チェスのゲームをマスターするために開発され、24時間以内に超人的なプレイレベルを達成し、それらのゲームの主要なプログラムを打ち負かすことができました。
また、このハードウェアをGoogle Street Viewのテキスト処理に使用したところ、5日以内にStreet Viewデータベースのすべてのテキストを抽出できました。
さらに、TPUは、RankBrainという名前の機械学習ベースの検索エンジンアルゴリズムで使用され、より関連性の高い検索結果を提供します。
Googleフォトでは、各TPUは1日に1億を超える画像を処理できます。
GoogleのTPUの他社競合製品
現在、NVIDIAは最新シリーズのGPU、TITANで機械学習プロセッサ市場を占有しています。これらは世界の最先端のアーキテクチャであるNVIDIA Voltaによって駆動され、新しいレベルのパフォーマンスを提供します。
たとえば、NVIDIA TITAN Vは、110 TeraFLOPSのパフォーマンスを実現できる211億個のトランジスタと640個のTensorコアを備えています。

Movidius(Intelが買収)は、電力に制約のあるデバイスで効率的に動作できるMyriad 2と呼ばれるVisual Processing Unit(VPUs)を製造しています。第3世代のVPUであるMyriad Xは、デバイス上のニューラルネットワークおよびコンピュータービジョンアプリケーションの有力な選択肢です。
2016年に、Intelは、トレーニングと推論の両方のためにNervanaという名前のAIプロセッサを発表しました。高速のオンチップおよびオフチップの相互接続を使用して設計されており、ニューラルネットワークパラメータが複数のチップに分散される真のモデル並列性を実現しています。
マイクロソフトは、クラウドでリアルタイムAIを提供するための深層学習プラットフォームであるProject Brainwaveに取り組んでいます。ディープニューラルネットワークの推論を加速するために、データセンターで高性能のフィールドプログラマブルゲートアレイ(FPGA)を使用しています。
AIチップには、IBM、ARM、Cerebras、Graphcore、Vathysなどが含まれます。まもなく、これらの機械学習チップが至る所で見られるようになるでしょう。





