・研究者達は、2つの入力画像の背後にある景色を推定する完全畳み込みディープネットワークを開発した。
・彼らは、入力画像の隠された部分を表示し、出力表示を予測するためにレイヤー表現を使用。
・当システムは、屋内・屋外両方の画像を扱うことが可能。
この10年間で、スマートフォンの写真技術は大きく変わりました。この変化は、優れたハードウェア技術・合成焦点・ダイナミックレンジイメージングなどの機能によってもたらされています。これらの技術革新は、従来のカメラ機能を再現するものです。
そして今、スマートフォンは深度センサーやマルチレンズを含む新しいタイプのセンサーを搭載し、従来のカメラを凌駕する機能を可能にしています。ステレオカメラは以前からありましたが、基線の小さな二眼カメラが市場に出回り始めました。また、目の距離ほどの間隔でデュアルカメラを搭載したVR機器では、ステレオ画像や動画を撮影できるものもあります。
こうしたステレオカメラの大いなる進化に刺激され、Googleの研究者は、iPhone 8やXのようなVR、ステレオ・デュアルレンズカメラで撮影した2枚の静止画から短いビデオクリップを作成する事ができる人工知能システムを開発しました。
グーグルはすでにAI分野をリードしています。ここ数年、目をスキャンして心臓病を予測するシステム、人間と区別できない音声AI、人間の暗号を打ち負かす別のAIを作るAI、さらには遠い宇宙で太陽系外惑星を発見するなど、数々の刺激的な研究を発表しています。
なぜ、こんなことができたのか?
研究者たちは、2枚の入力画像の向こう側にある景色を外挿することに注目しました。最初の課題は、透明度や反射を含む画像を扱うことです。次に、隠蔽されたピクセルをレンダリングすることです。
これらの問題に対処するため、彼らはディープラーニングシステムを用いて、膨大な量の視覚データから視界の外挿を行いました。目的は、与えられた2枚の画像を超えて外挿し、同じシーンの新しいビューを合成するためにグローバルなシーン表現を推論するディープニューラルネットワークを学習させることです。
まず、入力画像から出力画像を予測するために再利用可能なシーン表現を探す必要があります。次に、2つの入力画像において、障害物や隠蔽物を表示できる表現が必要です。これらの条件を満たすために、彼らはレイヤー表現であるマルチプレーン・イメージを開発しました。
学習データは世界で最も人気のある動画配信プラットフォーム「YouTube」から抽出しました。ステレオペアのほか、入力ステレオペアから少し離れた画像も追加で収集しました。
つまり、この研究には3つの重要な要素が含まれています。
1.ステレオ拡大のための学習フレームワーク。
2.マルチプレーン・イメージ(視界合成を行うためのレイヤー表現)。
3.ビュー合成を学習するためのオンラインビデオ
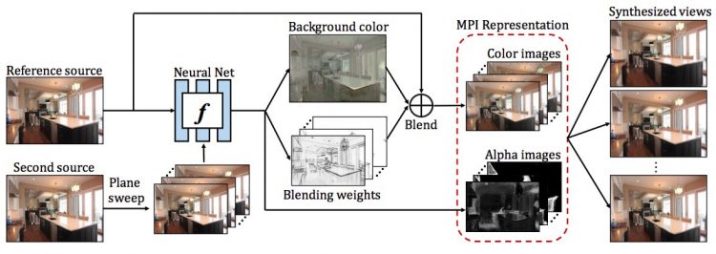
マルチプレーン表現を推測するために、完全畳み込みディープネットワークを使用しました。上図(システム概要)にあるように、各プレーンに対して、ネットワークはアルファ画像を予測します。参照元と予測された背景画像は、カラー画像をブレンドするために使用されます。
学習段階では、ネットワークはマルチプレーン画像表現を予測するように設定され、微分可能なレンダリングモジュールを使用してターゲットビューを再構築します。テスト段階では、各シーンに対して一度だけマルチプレーン画像表現を推論し、最小の計算で新しいビューを合成するため、さらに利用することが可能となります。
開発者は、NVIDIA Tesla P100 GPUとCUDAディープニューラルネットワークアクセラレーションTensor Flowフレームワークを使用して、7000以上の不動産 YouTube 動画をシステムに学習させました。
テスト実施
マルチプレーン画像に基づく視界合成システムは、大規模かつ多様なデータセットを学習し、屋内外両方の写真を扱うことができます。
ステレオカメラやスマートフォンで撮影したステレオ写真の狭い基線(1cm程度)を効率的に拡大することができ、従来の技術よりも優れた性能を発揮するといいます。
ただし、複雑な背景のディテールを正しい深度に配置するのが困難という、小さな欠点もあります。
研究者は、このシステムが、1~2以上の入力シーンの外挿や、多次元での視界移動を可能にする光場の生成など、さまざまなタスクを一般化できると考えています。