・Microsoftは、チューリング自然言語生成を紹介しました。これは、170億のパラメーターによる、世界で最も大きなモデルです。
・これは、テキストドキュメントの抽象的な要約や、質問に対する直接的な回答、完璧な文章のための言葉を生み出します。
・人が置かれている様々な状況において、このモデルは正確で直接的、流暢に応答します。
大規模な深層学習言語モデル(GPT-2やBERTなど)は、インターネット上で、利用可能なすべてのテキストで数十億のパラメーターを訓練されており、文書理解、会話エージェント、質問への返答などのさまざまな自然言語処理(NLP)タスクを強化しました。
より多様で包括的な事前訓練データを備えたより大きなモデルが、より少ない訓練サンプルでさえも、良く動作することが確認されています。したがって、タスクごとに新しいモデルを個別にトレーニングするのではなく、大規模な集中モデルをトレーニングし、さまざまなタスクでその機能を共有する方が効率的です。
この傾向に従い、Microsoftの研究員は、チューリング自然言語生成(T-NLG)という、170億のパラメーターによる世界最大のモデルを紹介しました。さまざまな言語モデリングベンチマークにおいて、既存の最新モデルよりも優れています。
T-NLGは、未完の文章の完成や入力したドキュメントの要約、質問に直接的な返答をするための言葉を生み出します。要約や質問への回答のため、文章からコンテンツを抽出している他のNLPシステムのようなものとは異なり、新しいモデルは異なる状況において、正確で直接的、そして流暢に応答します。

一節をコピーする代わりに、T-NLGは完全な文章で質問に直接回答します。
トレーニングT-NLG
1つのGPU(32GBメモリでも)は数十億のパラメーターを処理できないため、モデル自体を並列化するか、スライスに分割して複数のGPUでトレーニングする必要があります。
この研究では、研究者はNVIDIA DGX-2ハードウェアセットアップ(GPU間の通信を高速化するため)とテンソルスライス(4つのNVIDIA V100 GPUでモデルを壊すため)を活用しました。
DeepSpeedライブラリとZeroオプティマイザーを使用し、より少ないGPUで、T-NLGを非常に効率的にトレーニングすることができました。
標準タスクに対するパフォーマンス

次に、事前トレーニング済みのT-NLGのパフォーマンスを、LAMBADAの次の単語の予測精度(高いほど良い)とWikitext-103の複雑さ(低いほど良い)の2つの標準タスクで、他の強力なトランスフォーマー言語モデルと比較しました。その結果、どちらのケースでもT-NLG7のパフォーマンスの方が優れていたのです。
質問に回答するパフォーマンス

文法的正確性や事実的正確性などの品質をテストするために、研究者は人間のアノテーターの助けを借りました。彼らは、LSTMモデル(CopyNetのようなもの)で新しいモデルを比較しました。
アクティブな要約のパフォーマンス
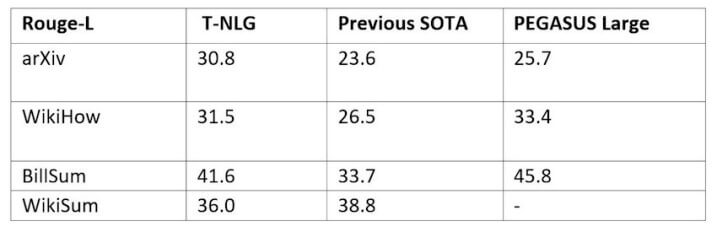
T-NLGは、さまざまなテキストドキュメント(Wordドキュメント、ブログ投稿、電子メール、PowerPointプレゼンテーション、Excelシートなど)に対し、人のように要約を作成できます。しかし、他の既存のNLPモデルに比べ、どのように優れているのでしょう。
新しいモデルをより汎用的にして、あらゆる種類のテキストを要約できるようにするために、研究者は、公開されている要約データセットでトレーニングをしました。彼らは、他の言語モデルをベースにしたPEGASUSという名前の大きなトランスフォーマーと、以前のバージョンを比較しました。今回は、自然言語処理での自動要約の評価に使用される一連のメトリックである、ROUGEスコアを報告しました。
アプリケーション
Microsoftは、会話型人工知能においてブレイクスルーを達成しました。今後数年間で、Microsoft Office suiteにT-NLGを統合するでしょう。これにより、電子メールやドキュメントを要約することでユーザーの時間を節約できるだけでなく、執筆支援を提供し、読者からのコンテンツについての質問に答えることも可能です。
さらに調査結果は、より正確で流暢なデジタルアシスタントとチャットボットへの道を開き、営業や、顧客関係管理を行う企業を支援するでしょう。