・マイクロソフトは会話型人工知能の分野で新記録を樹立しました。
・マイクロソフトは、様々な自然言語理解タスクにわたってテキスト表現を学習する、マルチタスクディープニューラルネットワークの強化版を開発しました。
堅牢かつ普遍的な言語表現は、さまざまな自然言語処理(NLP)タスクで適切な結果を得るために重要です。アンサンブル学習は、モデル一般化を強化するための最も効率的なアプローチの1つです。これまでのところ、開発者はこれを使用して、機械の読解から質問応答まで、さまざまな自然言語理解(NLU)タスクで最先端の成果を得ています。
しかしながら、そのようなアンサンブルモデルは、何百にも及ぶディープニューラルネットワーク(DNN)モデルを含み、実施するだけで莫大なコストがかかります。 GPTやBERTなどの事前にトレーニングされたモデルも、展開するのに非常に費用がかかります。例えば、GPTは15億個のパラメータを持つ48層のトランス層で構成され、BERTは3億4,400万個のパラメータを持つ24層のトランス層から構成されています。
2019年、マイクロソフトは独自の自然言語処理(NLP)アルゴリズムを開発し、マルチタスクDNNと名づけました。彼らは、このアルゴリズムをアップデートし、見事な結果を得ています。
知識の蒸留の拡張
研究チームは、知識の蒸留を用いて、いくつかの集合モデルを1つのマルチタスクDNNに圧縮しました。アンサンブルモデルを(オフラインで)使用して、トレーニングデータセット内のすべてのタスクに対してソフトターゲットを生成しました。ハードターゲットと比較して、訓練サンプルごとにより有益なデータを提供しています。
たとえば、「昨夜、ジョンとおしゃべりをしました」という文を考えてみましょう。このフレーズに伴う感情は、否定的なものではありません。しかし、「昨夜、私たちは興味をそそる会話をしました」という文章は、文脈によって否定的なものでも肯定的なものにもなりえます。
研究者らは、単一のMT-DNNを訓練するために、さまざまなタスクにわたって正しいターゲットとソフトターゲットの両方を使用しました。彼らは、cuDNNアクセラレーテッドPyTorchディープラーニングフレームワークを利用して、NVIDIA Tesla V100 GPUの新しいモデルの訓練とテストをしました。
結果
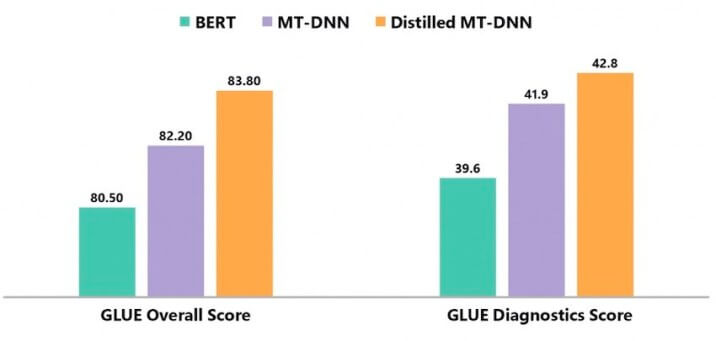
彼らは蒸留したMT-DNNと通常のMT-DNNおよびBERTを比較しました。その結果、蒸留されたMT-DNNは、幅広い言語現象に対するシステム性能のテストに使用されるGeneral Language Understanding Evaluation(GLUE)ベンチマークの総合スコアにおいて、両方のモデルを大幅に上回っています。
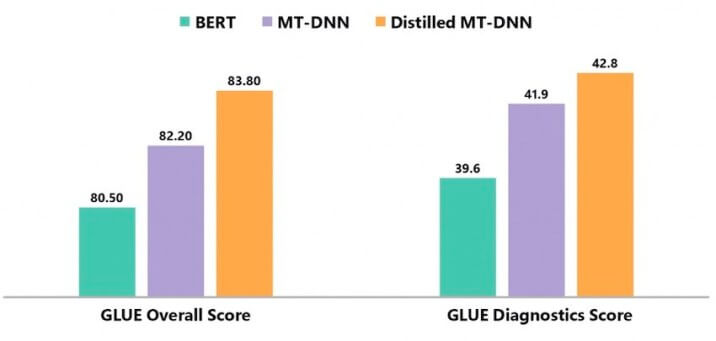
ベンチマークは、テキストの類似性、テキストの含意、感情分析、質問応答など、9つのNLUタスクで構成されています。データには、学術および百科事典のテキスト、ニュース、ソーシャルメディアなど、さまざまな情報源から抽出された数百の文章の組み合わせが含まれています。
この研究で行われたすべての実験は、蒸留されたMT-DNNを通して学習された言語表現が、通常のMT-DNNおよびBERTよりも、より普遍的で堅牢であることを明確に示しています。
研究者は、マルチタスク学習のために、より最適にハードコレクトターゲットとソフトなターゲットを組み合わせる方法を今後数年間で見つけようとします。また、複雑なモデルを単純なモデルに圧縮するのではなく、その複雑さに関係なく、モデルのパフォーマンスを向上させるために知識蒸留のより最適な使用方法を模索するでしょう。