・Googleは、混雑した場所でも特定の音声に焦点を当てることができる新しいAIを開発。
・視覚信号と聴覚信号の両方を組み合わせて、音声を分離。
・音声認識を前処理することによって、重複する話者に対してより良いビデオキャプションシステムを提供。
人間は、混雑した場所で特定の音声を拾うことが非常に得意で、その他の音を勝手にミュートしてしまいます。しかし、これは機械にとってとっても難しい問題!2人以上の人が話しているとき、あるいは背景に雑音があるときは、個々のスピーチを分離するのはまだ上手ではありませんでした。
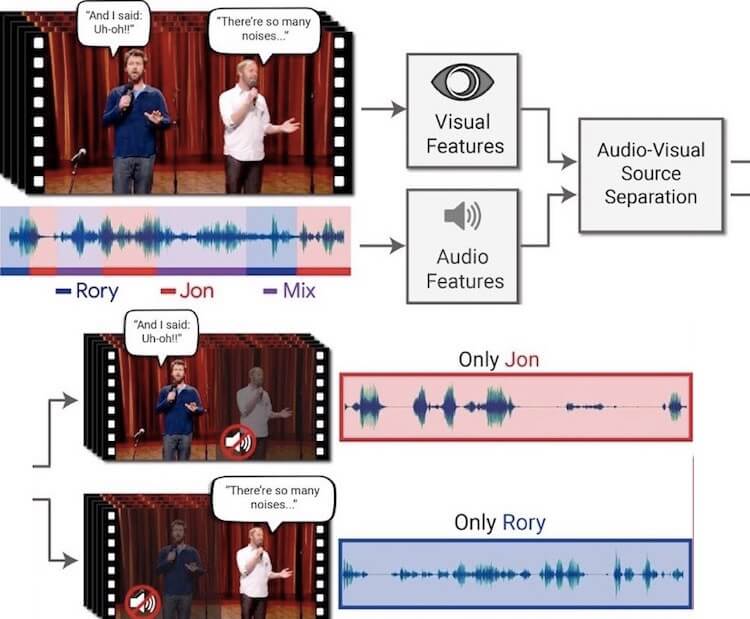
しかし現在、Googleは、音声と背景雑音の混合から単一の音声信号に焦点を当てることができる深い学習に基づく視聴覚モデルを開発したんです!!AIは、その他のすべての音を抑えながら、ビデオを分析したり、特定の人の声を高めたりすることができます。
特別なオーディオ形式やビデオ形式は必要なし。一般的なビデオ形式では、1つのオーディオトラックを使用して動作します。ユーザは、聴きたいビデオの中で特定の顔を選択することができ、あるいは、そのアルゴリズムに基づいてアルゴリズムを実行。
この技術は、映像の視覚信号と聴覚信号の両方を組み合わせて、音声を分離します。アルゴリズムは、口の動きに基づいて現在話している人を識別可能。混合した音声であっても音声を分離する品質を大幅に改善し、音声トラックを可視スピーカーと関連付けることが可能になりました。
これってすごいと思いませんか???
一体、どうやって作るの?
Googleの天才エンジニアたちは、YouTubeビデオを大量に収集し、トレーニングサンプルを制作するためのレクチャーを実施しました。そして、これらのビデオから2,000時間のクリップをフィルター処理。フィルター処理されたビデオは、音声を含んでいませんでしたが、聴衆の雑音がなく、音楽や背景の干渉が混在しています。

次に、このコンテンツを使用して、さまざまなソースからの音声と背景ノイズとの組み合わせを作成。彼らは、混合音声ビデオから個々の話者の声を分離するために、マルチストリームの畳み込みニューラルネットワークを訓練しました。
各フレーム(ビデオから抽出された)のスピーカのサウンドトラックと顔のサムネールのスペクトログラム表現は、両方ともニューラルネットワークに挿入されます。ネットワークは、聴覚信号と視覚信号を符号化し、それらを融合させて単一の視聴覚コンテンツを生成する方法を徐々に学習していきます。
一方、ネットワークは個々の話者に対して時間-周波数フィルターを提供することを学習します。そして、ノイズを含んだ入力スペクトログラムをフィルターに掛けて、きれいなスピーチを出力して、干渉やノイズを除去します。
実装の詳細
ネットワークは、TensorFlow(オープンソースマシン学習フレームワーク)に実装され、そのオペレーションは波形と短時間フーリエ変換を実行するために使用され、マスクレイヤを除くすべてのネットワークレイヤは、その後に修正されたリニア単位のアクティブ化を実行します。
すべての畳み込み層に対してバッチ正規化が実行されます。これを行うために、6サンプルのバッチサイズを使用し、5,000,000回のバッチ(ステップ)で訓練を実施。オーディオは16kHzに再サンプリングされ、ステレオオーディオはモノラルになり、短時間フーリエ変換が計算されます。
ちょっと難しい話になりますが、すべての面埋め込みは、トレーニングの前に2分の25フレームに再サンプリングされ、その結果、75面の埋め込みの入力視覚ストリームが生成されます。特定のサンプルでフレームが見つからなかった場合は、ゼロベクトルが採用されました。
アプリケーション
それではこのすごい技術、いったい、将来どのように使われていくのでしょうか??
実際のところ、ビデオの音声認識から、特に複数の人が話しているときの音声認識に至るまで、無数のアプリケーションに応用される可能性があります。さまざまなオーディオ環境で使用できるマイクの種類を増やすこともできるでしょう。今のところ、YouTubeとHangoutsの2つが主な候補になっている模様。最終的には、音声増幅のイヤホンやGoogleメガネにも適用されていくでしょう。
「Googleは、人間とは区別できない音声AIを開発する」
とんでもなくすごい話ですよね。
2年後には、音声認識を前処理することで、重複する話者に対してより良いビデオキャプションシステムを提供するでしょう。この機能によって、聴覚障害者がテレビ会議に参加したり、映画ビデオを楽しむことができる未来が待っています。