機械学習やARなどの技術革新を支える重要なプロセスと言えるのがデータサイエンスです。
データサイエンスとは、統計学、情報学、データ分析などのさまざまな手法を統合して、構造化データまたは非構造化データに隠された複雑なパターンを理解する研究分野です。情報科学、コンピュータサイエンス、およびドメインに関する知識などの多くの分野で研究された理論とテクノロジーを利用します。
近年では、さまざまな種類のデータから知識を得るためにインターネット上で利用できる高度なツールがたくさん開発されています。しかし中には使う価値のないようなツールも存在します。この記事では、研究者やビジネスアナリストがデータから有用な見解を引き出すために使える、最高のデータサイエンスツールをご紹介しています。
※このリストに含まれるのはデータサイエンスツールのみであり、データサイエンスを実装するためのプログラミング言語やスクリプトは含まれません
⑨ DataRobot
<長所>
・機械学習機能のスケールアップに最適
・オープンソースとプロプライエタリモデルの大規模なライブラリが含まれている
・困難とされる課題も解決可能
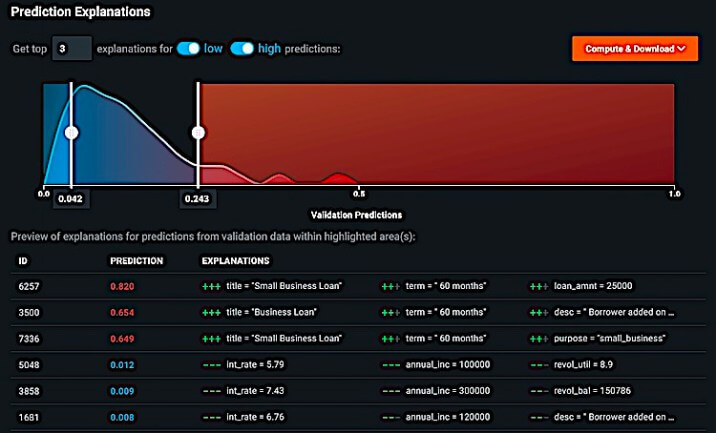
・視覚的にわかりやすく説明可能なAI
<短所>
・他のツールと比較してかなり高価
価格:プロジェクトの規模と難度次第(無料トライアルあり)
DataRobotは、何百もの最新の機械学習アルゴリズムを含んだツールであり、モデルの構築と開発のプロセスをしっかり監視・制御することができます。
使用を開始すると、さまざまなモデルから開発に適したモデルを選択することからスタートします。 DataRobot APIを使用することで、バッチデプロイやリアルタイム予測、Hadoopでのスコアリングが必要であっても、任意のモデルをすばやく実際の環境に移行できます。 プロセスをカスタマイズするために、コードを数行追加する必要がある場合もあります。
DataRobotには、転移学習や機械学習などを最大化するだけでなく、利益曲線、データ主導の予測、ガバナンスを備えたワンクリック展開などのビジネスにおいて役立つ機能も含まれています。このプラットフォームは、数百万の製品の売上予測から複雑なゲノムデータの操作まで、幅広いデータサイエンスの問題の解決に適しています。
⑧ Alteryx
<長所>
・直感的なインターフェース
・すぐに使用できる予測モデリングテンプレート
・複雑なクエリの視覚化
・ドラッグアンドドロップによるデータの準備、ブレンディング、分析
・OCRとテキスト分析機能
<短所>
・高価
・アシストモデリング機能には追加のライセンスが必要
価格:ユーザーあたり年間2300ドルから (30日間の無料トライアルあり)
Alteryxは、分析、機械学習、データサイエンス、プロセス自動化を兼ね備えたエンドツーエンドプラットフォームです。このツールを使えば、何百ものプラットフォーム(Oracle、Amazon、Salesforceを含む)からデータを取得ことができ検索に費やす時間が減るため、分析により多くの時間を割けるようになります。
ビジュアルプログラミングのインターフェイス(Analytic Process Automation)を使用して、必要な機能を作成しアクセスし、選択しながらデータを探索することができます。事前に構築された構成オプションを使用したり、分析ワークフローに独自のPythonまたはRコードを追加することにより、個々の分析要素に細かな変更を加えることが可能になります。
Alteryxを使用すれば、自動化されたモデルトレーニング要素を使用して、機械学習モデルとパイプラインのプロトタイプを迅速に作成することができます。これは、問題解決とモデリングの全過程を通じてデータを簡単に視覚化するのに役立ちます。つまり、プロセスの任意のステップから、テーブル、チャート、およびレポートを自動的に作成することができるのです。
このプラットフォームは、どんな規模の企業であっても利用できます。特に中堅企業の場合は、新しい洞察を得て影響力のある結果に導いてくれるでしょう。
⑦ H2O.ai
<長所>
・分散型のメモリ内機械学習
・大型モデルの導入が容易
・機械学習ワークフローを自動化
・既存のビッグデータインフラストラクチャで作動
<短所>
・データ処理オプションが限定されている
・文字による説明が少ない
価格:プロジェクトの規模と難度次第(14日間の無料トライアルあり)
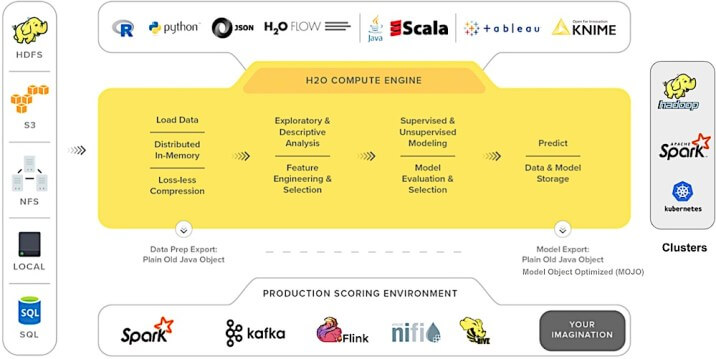
H2Oは、線形的なスケーラビリティを備えたオープンソースの分散型機械学習ツールです。 一般化線形モデル、深層学習、勾配ブーストマシンなど、一般的な統計および機械学習アルゴリズムのほぼすべてをサポートしています。 Spark、Azure、Spark、HDFS、およびその他のさまざまなソースから、メモリ内の分散キーバリューストアにデータを直接取り込みます。
モデルを構築するには、コーディングを必要としないR / Pythonプログラミング言語またはH2OFlow(グラフィカルノートブック)のいずれかを使用できます。
H2O AutoMLを使用すると、機械学習モデルのトレーニングと評価を簡単に行うことができます。 これにより、データサイエンスのタスク(アルゴリズムの選択、反復モデリング、ハイパーパラメータの調整、特徴の生成、モデルの評価など)を自動化し、重大な課題に集中することができます。
このプラットフォームはPythonおよびRコミュニティの間で非常に人気があり、18,000を超える組織で使用されています。
⑥ D3.js
<長所>
・軽量、高速
・データの視覚化を自在にコントロール可能
・SVGやHTMLなどのWeb標準環境で作動
・再利用可能な関数と関数ファクトリが多数標準搭載
<短所>
・ドキュメントは改善の余地あり
価格:無料
D3.js(D3=Data-Driven Documentsの略)は、Webブラウザ上で動的でインタラクティブなデータ視覚化を実現するためのJavaScriptライブラリーです。すでに設計された関数を使用して、SVGオブジェクトの作成やカスタマイズ、動的効果の追加が可能です。 これらのSVGオブジェクトに大きなデータセットを添付して、テキスト/グラフィックの図やグラフを作成できます。
D3には標準の視覚化形式はありませんが、 円グラフやグラフからHTMLテーブルや地理空間マップまで、あらゆるものを設計することができます。
データは、CSVやJSONなどのさまざまな形式に変換することができます。 JavaScriptのコードを記述して他のデータ形式を読み込んだり、公式やコミュニティによって開発された様々なモジュールを通じてコードを再利用したりすることもできます。
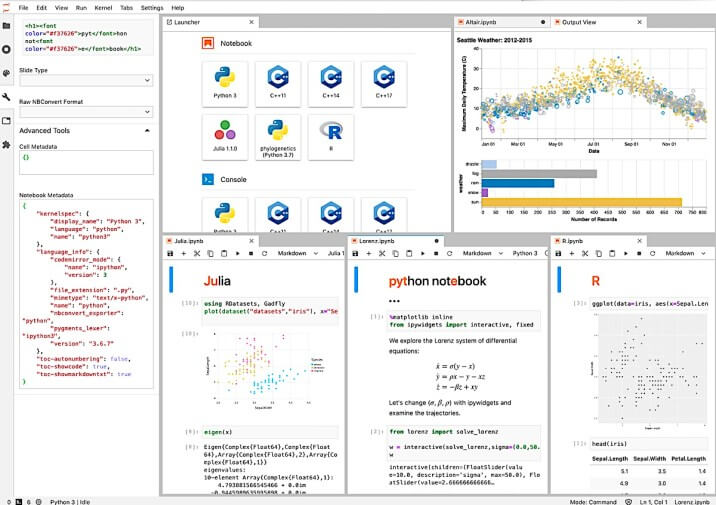
⑤ Project Jupyter
<長所>
・軽量で使いやすい
・PythonMathライブラリの優れたサポート
・事前に定義された視覚化モデル
・データフローの編集と追跡が簡単
・チェックポイントの自動生成
<短所>
・複数カーネルでの処理は難しい
・他ツールとのコラボレーションは限定的
価格:無料
Project Jupyterは、オープンソースのインタラクティブなWebツールであり、ソフトウェアコード、計算出力、マルチメディアリソース、および説明テキストを1つのドキュメントに組み合わせるために使用できます。
ツール自体は何十年も前からあるものですが、ここ数年で爆発的に人気になりました。 Jupyterは、インタラクティブコンピューティング用のオープンソースソフトウェア、オープンスタンダード、およびサービスを開発するためのさまざまな製品を提供しています。
・Jupyter Notebook:ライブ方程式、コード、視覚化、およびナラティブテキストを含むドキュメントを作成して共有できます
・Jupyter Kernel:コードの実行や検査などの複数のリクエストを処理可能です
・JupyterLab:直感的なユーザーインターフェイスを持ったターミナル、ファイルブラウザー、テキストエディターなどを様々な出力形式で利用できます
・JupyterHub:複数の単一のJupyter Notebookサーバーを生成、管理、およびプロキシすることにより、複数のユーザーをサポートします
これらのツールは全て無料であり、数値シミュレーション、データクリーニング、統計モデリング、データの視覚化などをブラウザから直接行うことができます。
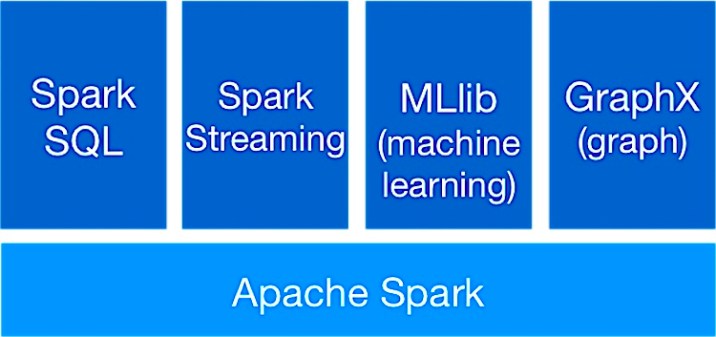
④ Apache Spark
<長所>
・堅牢かつフォールトトレラント
・大規模なデータセットの機械学習モデルを効率的に実装できる
・複数のデータソースからデータを抽出
・多言語対応
<短所>
・学習曲線が高い
・データの視覚化機能が不十分
価格:無料
Apache Sparkは、大規模なデータセット用に構築されたオープンソースのデータ処理エンジンです。最先端のDAGスケジューラー、クエリオプティマイザー、および効率的な実行エンジンを使用して、バッチデータとストリーミングデータの両方で高いパフォーマンスを実現します。最大100倍高速にワークロードを実行できます。
Sparkは、GraphX、機械学習用のMLlib、Sparkストリーミング、SQLおよびDataFrameを含む多数のライブラリを強化します。これらのライブラリはすべて、1つのアプリケーションにシームレスに統合可能です。
このツールには、階層的なマスタースレーブアーキテクチャが搭載されています。 「スパークドライバー」は、複数のワーカー(スレーブ)ノードを管理し、データ結果をアプリケーションクライアントに配信するマスターノードです。
Sparkの基本的な構造は、復元力のある分散データセットであり、クラスター内の複数のノードに分散して並行して作業できる、フォールトトレラントなコンポーネントとなっています。
80を超える高レベルの演算子を提供し、並列アプリケーションの開発を容易にします。さらに、R、Python、Scala、SQLシェルからSparkをインタラクティブに使用することもできます。
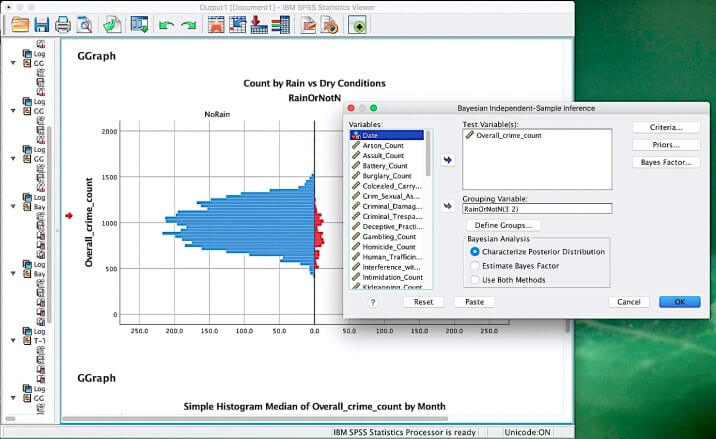
③ IBM SPSS Statistics
<長所>
・データ抽出の自動化
・線形および非線形関係の正確なモデリングが可能
・異常の検出と予測機能
・Rアルゴリズムとグラフィックスのサポート
<短所>
・役に立つ機能のほとんどが有料
・インターフェースの古さ
価格:月額99ドルから(30日間の無料トライアルあり)
SPSS Statisticsは、データが提供する貴重な情報を最大限に活用できる強力な統計ソフトウェアプラットフォームです。 これは、詳細な分析、仮説検定、および予測分析を通じて、ビジネスおよび研究の問題を解決するように設計されています。
SPSSは、スプレッドシート、データベース、ASCIIテキストファイル、およびその他の統計パッケージからデータを読み書きできます。 SQLおよびODBCを介して外部リレーショナルデータベーステーブルの読み取りと書き込みを行うことができます。
SPSSの主要な機能のほとんどは、プルダウンメニューからアクセスできます。 4GLコマンド構文言語を使用して、反復的なタスクを簡素化し、複雑なデータ操作と分析を処理できます。
このプラットフォームは、データを理解し、傾向を分析し、仮定を検証し、正確な結論を出すことができるため、市場調査員、データマイニング担当者、政府、調査会社などでの使用に向いています。
② RapidMiner
<長所>
・機械学習アルゴリズムの豊富なセットが付属しています
・直感的なGUI
・必要に応じて完全自動化可能
・拡張機能により他のツールと連携可能
・包括的なチュートリアル
<短所>
・グラフがやや時代遅れ
・大規模なデータセットの処理には時間がかかる
価格:無料
オープンコアモデルで開発されたRapidMinerは、データの準備、結果の視覚化、モデルの検証、最適化など、機械学習手法のすべてのステップに対応しています。
RapidMinerは、独自のデータセットのコレクションに加えて、大量のデータを保存するためにクラウドにデータベースをセットアップするためのいくつかのオプションを提供します。 NoSQL、Hadoop、RDBMSなどのさまざまなプラットフォームからデータを保存およびロードできます。
データの前処理、視覚化、クリーニングなどの一般的なタスクは、コードを1行も記述せずに、ドラッグアンドドロップオプションを介して実行できます。
RapidMinerのライブラリ(1,500を超える関数とアルゴリズムを含む)は、あらゆるユースケースに最適なモデルを保証します。また、不正検出、予知保全、顧客離れなどの一般的なユースケースで利用できる事前に設計されたテンプレートが付属しています。
このプラットフォームは、ビジネスおよび商用ソフトウェアの開発、およびラピッドプロトタイピング、教育、トレーニング、および研究において広く使用されています。 700,000人を超えるアナリストがRapidMinerを使用して、収益を増やし、運用コストを削減し、リスクを回避しています。
① Apache Hadoop
<長所>
・分散環境で動作するため、拡張性が高くスケーラブル
・フォールトトレランス
・クラウド環境またはコモディティハードウェアで使用可
・任意の形式でのデータ保存が可能
<短所>
・他の最新のフレームワークよりも効率が悪い
・セットアップ、保守、およびアップグレードには、かなりの専門知識が必要
価格:無料
Hadoopは、企業がデータを保存、処理、分析する方法を根本的に変えるオープンソースのユーティリティソフトウェアです。従来のプラットフォームとは異なり、さまざまな種類の分析ワークロードを同じデータで同時に、業界標準のハードウェアで大規模に実行できます。
Hadoopは、大規模なデータセットと分析ジョブをコンピューティングクラスター内のノードに分散し、並行して実行できる軽度の作業に変換します。構造化データと非構造化データの両方を処理し、単一のマシンから数千のデバイスにスケールアップできます。
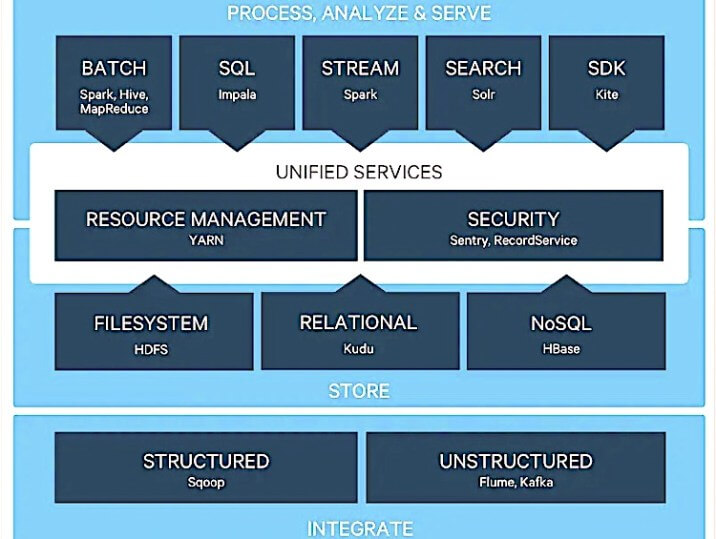
このツールには、5つの主要なモジュールがあります。
・Hadoop分散ファイルシステム(HDFS):フォールトトレラントな方法でノード間で大規模なデータセットを保存できます
・Yet Another Resource Negotiator(YARN):タスクの計画、クラスターリソースの管理、およびHadoopで実行されるジョブのスケジューリングが行えます
・MapReduce:ビッグデータセットの並列計算を可能にするビッグデータ処理エンジンおよびプログラミングモデルです
・Hadoop Common:他のHadoopモジュールに必要なライブラリとユーティリティで構成されています
・Hadoop Ozone:数十億の小さなファイル用に最適化されたオブジェクトストアです
全体として、Hadoopは新しいデータ形式(ソーシャルメディアにおけるユーザの反応やクリックストリームデータなど)を組み込んでおり、アナリストがより優れたリアルタイムのデータ主導の意思決定を行うのに役立ちます。
ここからは、その他の優れたデータサイエンスツールをご紹介しましょう。
10.Tableau
最適な用途:中小企業でのデータの視覚化と分析
Tableauは、データを表示および理解できる視覚分析プラットフォームです。 接続およびデータのフェッチが可能な幅広いデータソースオプションを提供します。
Tableauの最も優れている点は、意味のある情報を抽出するためにコーディングや技術的なスキルを必要としないことです。 UIベースの機能を使用して、カスタムダッシュボードを生成し、レポートを分析できます。 Tableauは、その使いやすさと高度な視覚化により、データサイエンティスト、アナリスト、経営幹部、教師の間で関心を集めています。
11. Databricks Lakehouse
最適な用途:データサイエンティストとエンジニアの共同作業
Databricks Lakehouseは、すべてのデータ、分析、AIワークロードを単一のプラットフォームに統合します。 これにより、ビジネスインテリジェンスツールをソースデータで直接使用できるようになり、待ち時間が短縮され、コスト効率が向上します。
このプラットフォームは、機械学習、SQL、分析など、幅広いワークロードをサポートしており、 AWS、Azure、GoogleCloudとシームレスに統合することができます。
オープンソースとオープンスタンダードに基づいて構築されたDatabricksのネイティブコラボレーション機能は、チーム間で作業し、より迅速にイノベーションを起こす能力を強化します。全体として、データサイエンスのビジョンを加速し、ロードマップを超えて見るのに役立ちます。
12.TIBCOデータサイエンス
最適な用途:学生や学者向け、高度なデータサイエンス、統計、機械学習のワークフローの構築
TIBCOデータサイエンスツールを使用することで、データの準備とモデルの作成から展開と監視まで、機械学習アルゴリズムを使用して面倒なタスクを自動化し、ビジネスにおける最適なソリューションを導くことができますj。
デスクトップベースのUIは16,000を超える機能を備えており、高度な高度な分析ワークフローを作成するために使用できます。 R、Python、およびその他のノードをパイプライン内に統合するオプションもあります。
さらに、組み込みノードを使用すると、グラフ、テキスト分析、時系列、回帰、ニューラルネットワーク、統計的プロセス制御、および多変量統計にアクセスできます。TIBCOは、ヘルスケア、製薬、製造、金融、保険などの業界におけるエンタープライズガバナンスの広範なサポートも提供しています。
13. Weka
最適な用途:実際のデータマイニング問題の解決
Wekaは、データ分析と予測モデリングのための視覚化ツールとアルゴリズムのセットです。 それらはすべてGNU General Public Licenseの下で無料で利用できます。
具体的には、Wekaには、データの前処理、分類、回帰、クラスタリング、および視覚化のためのツールが含まれています。 しばらくコーディングに触れていない人のためにWekaはGUIを完備しており、データサイエンスを簡単に活用するのに役立ちます。
ユーザーは、さまざまなアルゴリズムを適用してデータセットを実験し、どのモデルが最良の結果をもたらすかを確認できます。 また、視覚化ツールを使用してデータを検査することができます。
よくある質問
・データサイエンス、AI、ML(機械学習)の違いは何ですか?
データサイエンスは、構造化データと非構造化データの前処理、分析、視覚化を含む幅広い研究分野を指します。 データから得られた洞察は、さまざまなアプリケーションドメインに適用されます。
人工知能とは、機械に対し、何らかの方法で人間の行動を模倣することを教えることを意味します。 AI研究の目標には、知識表現、計画、学習、推論、自然言語処理、知覚、およびオブジェクトを操作する機能が含まれます。
機械学習はAIと呼ばれるものの一つであり、データとアルゴリズムを使用して人間の学習方法を模倣する方法に焦点を当てています。 MLモデルでは、取得するデータ(トレーニングデータとも呼ばれる)が多いほど、明示的にプログラムされていなくても、より正確に予測を行うことができます。
・データサイエンスに含まれるステップは何ですか?
データサイエンスには、6つのステップが含まれ、繰り返されます。
1. 計画:プロジェクトとその推定結果を定義します。
2. データモデルの構築:適切なデータサイエンスツールを使用して、機械学習モデルを作成します。
3. 評価:評価指標と視覚化を使用して、新しいデータに対するモデルのパフォーマンスを測定します。
4. 説明:機械学習モデルの内部メカニズムを簡単に解説します。
5. デプロイ:十分にトレーニングされたモデルを安全でスケーラブルな環境に展開します。
6. モデルを監視して、正しく機能していることを確認します。
・データサイエンスツールの選定において考慮すべきことは何ですか?
データサイエンスプラットフォームにおける留意すべき主な機能は次のとおりです。
1.複数のユーザーが同じモデルで一緒に作業できるか
2.最新のオープンソースアプリケーションがサポートされているか
3.スケーラブルであるか
4.面倒なタスクを自動化できるか
5.モデルを本番環境に簡単にデプロイする機能が搭載されているか
・データサイエンスはビジネスにどのように役立ちますか?
データサイエンスは、企業の健全性を分析する上で主要な役割を果たします。生データから貴重な情報を抽出し、会社の製品とサービスの成功率を予測します。また、製造プロセスの非効率性を特定し、適切な対象者を対象とし、組織に適切な人材を採用するのにも役立ちます。
一部のセクターでは、データサイエンスを使用してビジネスのセキュリティを強化し、機密情報を保護しています。たとえば、銀行は機械学習アルゴリズムを使用し顧客の通常の財務活動に基づいて不正を検出します。これらのアルゴリズムは、手動による調査よりも不正の特定においてはるかに効果的かつ正確であることが証明されています。
GlobalNewswireのレポートによると、世界のデータサイエンスプラットフォーム市場は2026年までに2,240億ドルに達し、31%のCAGRで成長すると報告されています。